 2023-12-13 10:36
2023-12-13 10:36
阿里最新AI视频生成模型DreaMoving又整活儿 :一张人脸图+一句提示词就能让纸片人动感起舞,还可随心生成服装与背景
继Animate Anyone之后,阿里又一项“舞蹈整活儿”论文火了——这一次更离谱,连人像写真都不需要了,只需一张小姐姐的脸部照片、一句话提示词描述,就能让你在任何地方跳舞!
?前情提要:

12月最新开源AI图生视频项目 - Animate Anyone:一张图片生成一段毫无破绽的舞蹈视频,跳舞主播快要下岗了!
分享一个GitHub上超级厉害的开源AI项目——Animate Anyone,只需要一张图片和一些姿势指导,就可以为任何人快速制作视频或直播。
例如,下面这段《擦玻璃》的舞蹈视频:

你所需要做的就是“投喂”一张人像,以及一段提示词:
“一个女孩,微笑着,在秋天的金色树叶中跳舞,穿着浅蓝色的连衣裙。”
而且随着prompt的变化,人物背景和身上的衣服也会随之发生改变。例如我们再换两句:
“一个女孩,微笑着,在木屋里跳舞,穿着毛衣和长裤。”
“一个女孩,微笑着,在时代广场跳舞,穿着连衣裙般的白衬衫,长袖,长裤。”

这便是阿里巴巴AI团队最新的一项AI视频生成研究课题——项目名称叫「DreaMoving」,主打的就是让任何人、随时且随地地跳舞。

而且不仅是真人,就连卡通动漫人物也都是可以hold住的哦~

项目一出,也是引发了不少网友的关注,有人在看过效果之后直呼“Unbelievable”~
那么如此效果,这项研究又是如何做到的呢?
虽然像Stable Video Diffusion和Runway Gen-2等文本到视频(text-to-video,T2V)模型的出现,在视频生成方面取得了突破性进展,但现在仍然有诸多挑战需要面对。
例如在数据集方面,目前缺乏开源的人类舞蹈视频数据集以及难以获得相应的精确文本描述,这就使得让模型们去生成多样性、每帧一致性、时长更长的视频成为挑战。
并且在以人为中心的内容生成领域,生成结果的个性化和可控性也是关键因素。

面对这两大难点,阿里团队先从数据集着手做处理。
研究者们首先从互联网收集了大约1000个高质量的人类舞蹈视频。然后,他们将这些视频分割成大约6000个短视频(每个视频8至10秒),以确保视频片段中没有转场和特殊效果,这样有利于时间模块的训练。
此外,为了生成视频的文本描述,他们使用了Minigpt-v2作为视频字幕器(Video Captioner),特别采用了“Grounding”版本,指令是详细描述这个帧。
基于关键帧中心帧生成的字幕代表了整个视频片段的描述,主要是准确描述主题和背景内容。
在框架方面,阿里团队则是提出了一个名叫DreaMoving、基于Stable Diffusion的模型。它主要由三个神经网络来构成,包括去噪U-Net(Denoising U-Net)、视频控制网络(Video ControlNet)和内容引导器(Content Guider)。
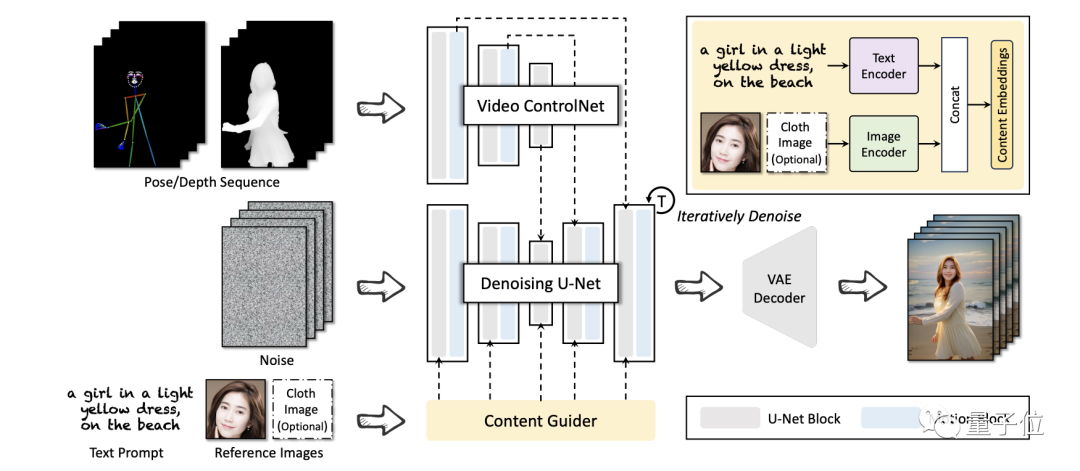
其中,Video ControlNet是在每U-Net块之后注入运动块(Motion Block)的图像控制网络,将控制序列(姿态或深度)处理为额外的时间残差。
Denoising U-Net是一种衍生的Stable-Diffusion U-Net,带有用于视频生成的运动块。
而Content Guider则是将输入文本提示和外观表情(如人脸)传输到内容嵌入中。
在如此操作之下,DreaMoving便可以在给定引导序列和简单的内容描述(如文本和参考图像)作为输入的情况下生成高质量、高保真度的视频。

不过很可惜的一点是,目前DreaMoving项目并没有开源代码。感兴趣的小伙伴可以先关注一波,坐等代码开源了~
项目介绍:
GitHub源代码:
相关文章
近期文章
更多


 Altman
Altman








