 2023-06-02 18:54
2023-06-02 18:54
中文语言大模型的现实窘境:缺乏高质量的语料库与开源数据集
AI奇点网6月2日报道丨为什么国内的语言大模型如雨后春笋般萌发,但是十分好用又能媲美ChatGPT的几乎没有呢?每天几乎都能从各大媒体的评论区听到类似的声音——“这一看就是ChatGPT套壳”“又是拿国外开源的大模型然后谎称是自研吧”之类的评价。

诚然,目前国产的大模型还有诸多需要追赶国际先进企业的差距。业内人士对这个现象的解释是,高质量的中文数据集实在紧缺,训模型时只能直接购买外文标注数据集或者直接采集开源的国外语料库作为外援。一旦“进口语料”加入的训练参数量多了,就会出现跟ChatGPT相似的回答方式。
业内渐渐形成共识:通往AGI的道路,对数据数量和数据质量都将持续提出极高的要求。
目前的国际主流大模型,参数数据集主要以英文为主,如Common Crawl、BooksCorpus、WiKipedia、ROOT等,最流行的Common Crawl中文数据尽然只占据4.8%,你要想想,中国是一个14亿人口大国,竟然凑不出一个强大的语料库,多少有点男子国足的窘境。
目前的中文数据集是什么情况?公开数据集不是没有,近2个月来,国内不少团队先后开源了中文数据集,除通用数据集外,针对编程、医疗等垂域也有专门的开源中文数据集发布。开源的还包括MSRA-NER、Weibo-NER等,以及GitHub上可找到的CMRC2018、CMRC2019、ExpMRC2022等存在,但整体数量和质量,和英文数据集相比可谓九牛一毛。并且其中相当一部分的内容已经非常陈旧。
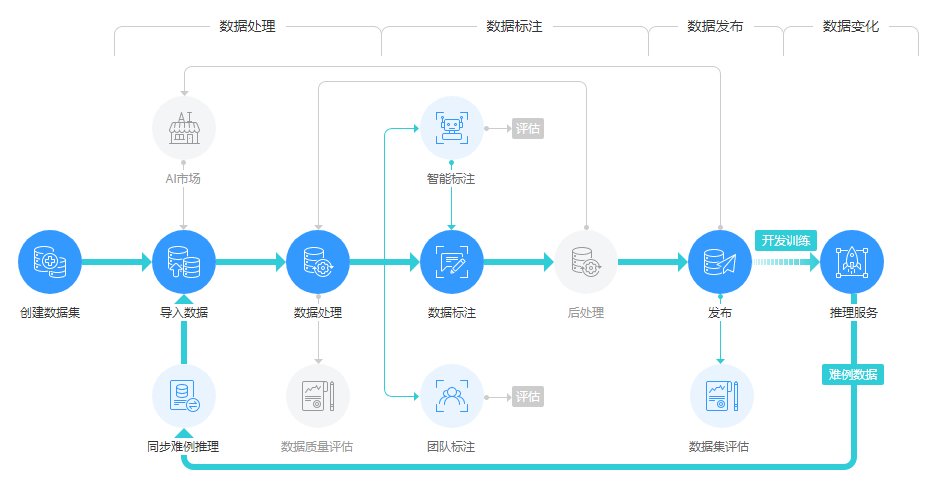
要想尽快训练出中文大模型,行之有效的解决方法之一,是直接用英文数据集训大模型。不嫌麻烦的话,甚至可以给模型接一个翻译软件,把所有语言都转换成英语,然后把模型的输出转换为中文,再返回给用户。但是这种转译的方法是不能满足中文博大精深的语言系统,也无法翻译出古诗词和古典经文还有成语,存在极大的文化冲突。

国内不少大模型团队决定走自己的第二条路,着手利用私有数据库做数据集。比如:百度有内容生态数据,腾讯有公众号数据,知乎有问答数据,阿里有电商和物流数据。这些具备较强的社交属性平台的训练团队选择先将这些收集到的人类沟通数据进行严格搜集、整理、筛选、清洗和标注,能保证训出模型的有效性和准确性。
不具备社交属性的企业就用爬虫工具从全网爬数据,华为为了打造盘古大模型,从互联网爬取了80TB文本,最后清洗为1TB的中文数据集;浪潮源1.0训练采用的中文数据集高达5000GB;天津超算中心的天河天元大模型也在全域搜集整理网页数据,同时集成各种开源的数据集。值得注意的是,除了预训练数据,目前阶段人类反馈数据同样不可或缺。
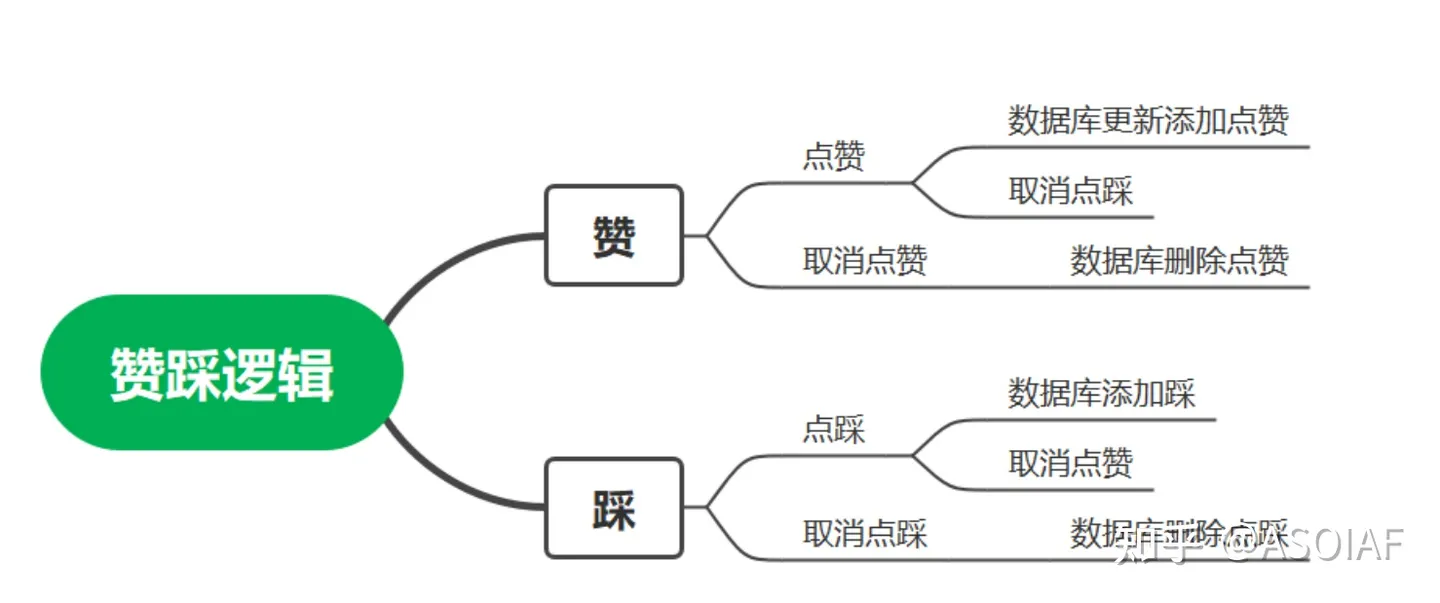
必须强调的是,光有巨量的中文数据集还是不够的,还需要有人为AI提供用户反馈。提供人类反馈最直接的办法,就是告诉AI助手“你的回答不对”,或者直接在AI助手生成的回复旁边点赞或踩一踩。

先用起来就能先收集一波用户反馈,让雪球滚起来,这就是为什么大家都抢着发布大模型的原因之一。现在,国内的类ChatGPT产品,从百度文心一言、复旦MOSS到智谱ChatGLM,都提供了进行回答结果的用户反馈按钮。所以建议各位致力于希望中国AIGC产业崛起的小伙伴们,当遇到AI回答出现错误或者不令人满意的时候,可以高抬贵手点一个赞或者点一个踩。
相关文章
近期文章
更多

 Altman
Altman

 雷小军
雷小军

 yaoyao
yaoyao





