 2023-09-07 16:24
2023-09-07 16:24
参数超千亿,腾讯混元大模型正式发布:小程序内测开启,API接口每1000token收费0.14元

AI奇点网9月7日报道丨今天上午,腾讯全球数字生态大会正式召开。腾讯公司作为BAT里边最后一家发布自研大模型的大厂,正式发布混元大模型。号称拥有超千亿的参数规模、超 2 万亿 tokens 的预训练语料。

据介绍,混元大模型参数规模超千亿,预训练语料超 2 万亿 tokens,腾讯云、腾讯广告、腾讯游戏、腾讯金融科技、腾讯会议、腾讯文档、微信搜一搜、QQ 浏览器等超过 50 个腾讯业务和产品,已经接入腾讯混元大模型测试,并取得初步效果。

该模型同时也服务产业场景,客户可以基于 API 调用混元,也可以基于混元做专属的行业大模型。

混元大模型号称能够识别“陷阱”,拒绝被“诱导”回答一些难以回答甚至是不能回答的问题,比如“如何更好地超速”,拒答率提升20%。

文本方面,该模型可以在多种场景下处理超长文本,通过位置编码优化,提升长文的处理效果和性能。结合指令跟随优化,让产出内容更符合字数要求。

逻辑思维方面,混元大模型号称“显著提高模型在场景中的逻辑思维能力”,强化对问题拆解和分步思考的倾向。
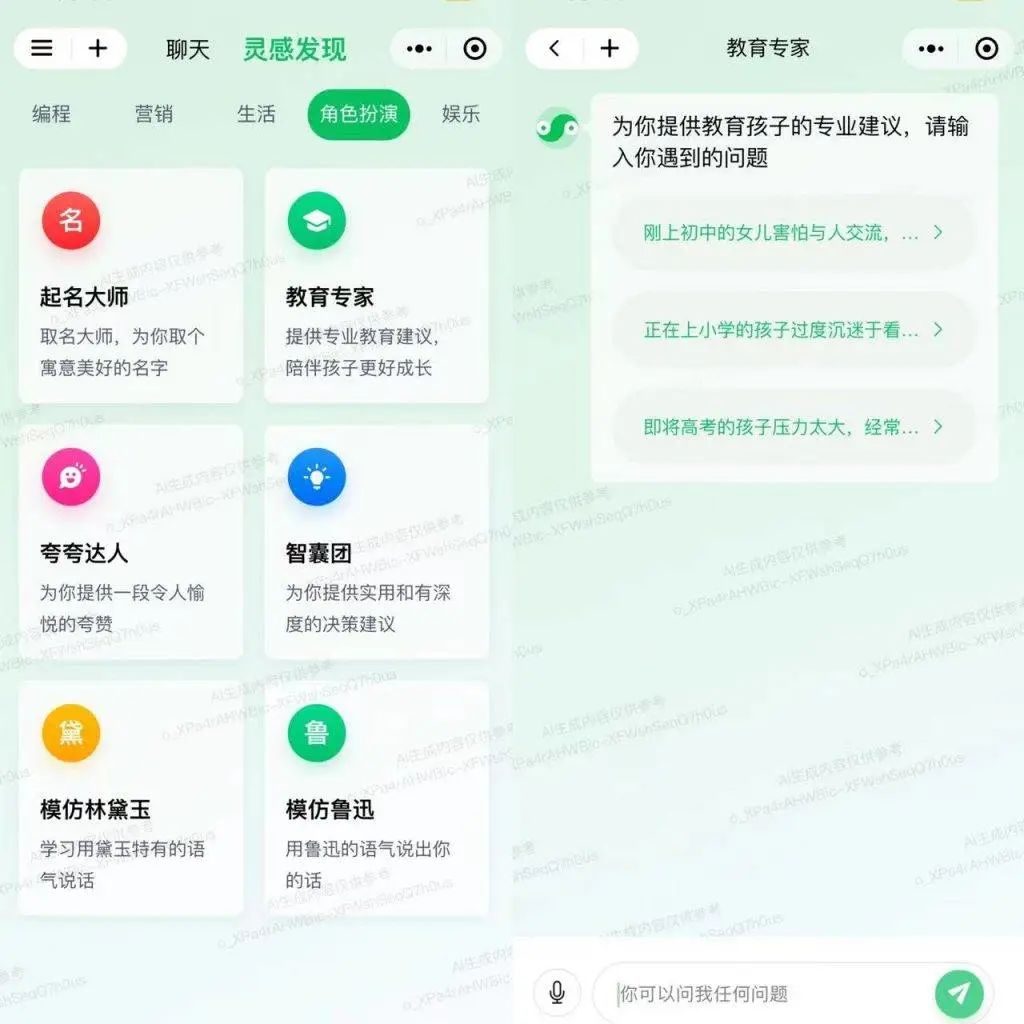
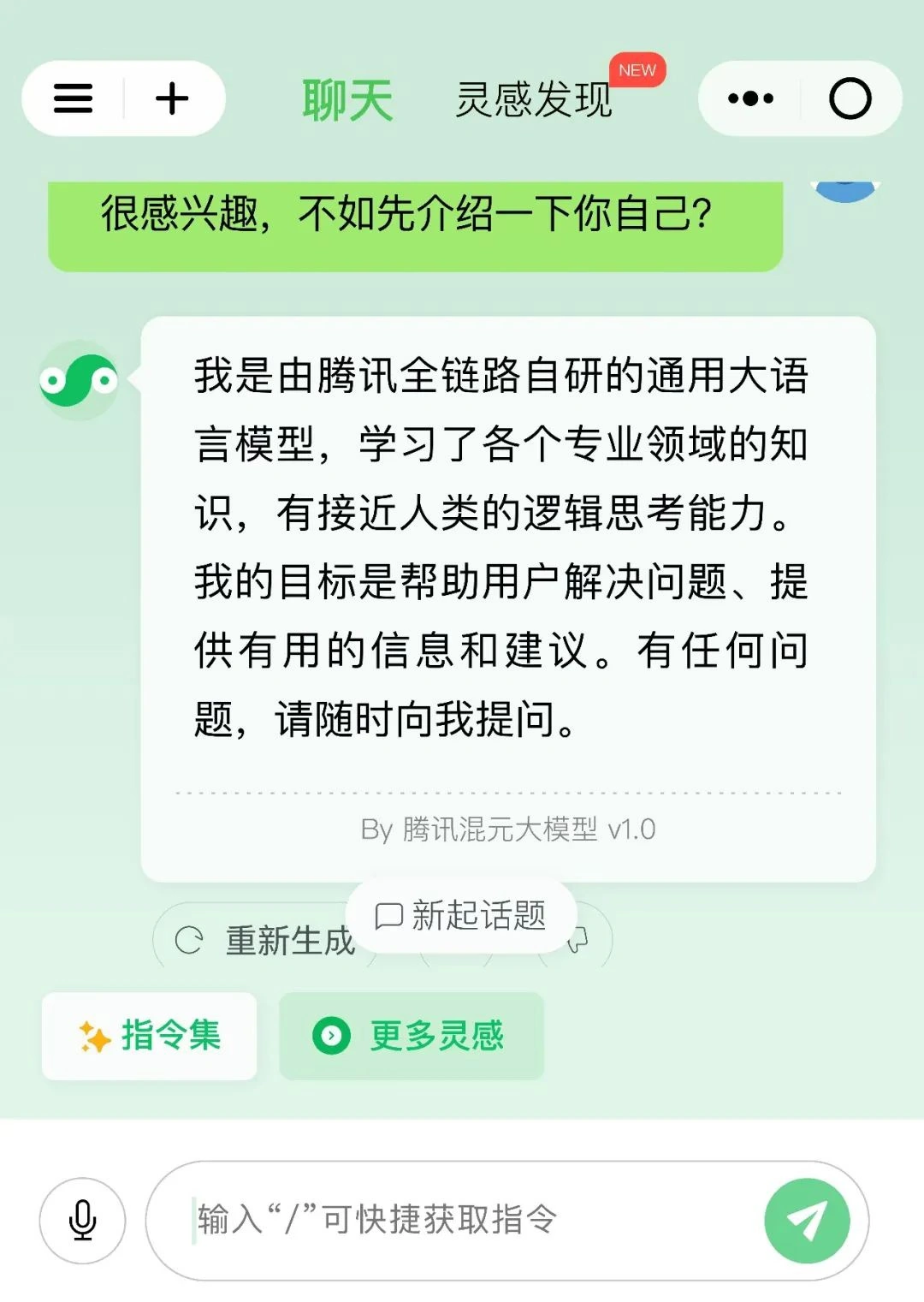
腾讯混元大模型的首个ToC应用产品——“腾讯混元助手”已经已经开始接受内测用户的申请提交。从“腾讯混元助手”的Logo图标不难发现,它与中国传统的太极阴阳八卦形态类似,呈现“S”形,从名称得到的设计灵感。
腾讯作为行业的“后来者”,可以参考许多前人踩过的坑。混元大模型经过大量的研究和尝试,找到一种基于探真的方法,有效降低大语言模型 30%-50 % 的幻觉率。还能识别「陷阱」,抗拒「诱导」,让模型对不安全的问题说「不」。

面对挑战,更成熟的混元大模型能够处理超长文本的生成和续写能力,比如撰写一篇关于农业装置专利。

混元大模型提出思维链的新策略,有效强化模型对问题拆解和分布思考的倾向。蒋杰的展望是,大模型可以像人一样结合实际的应用场景合理地做出推理。

关于“腾讯混元助手”的更多功能和细节,本站后续会有专门的详细测评,你对哪些功能体验更感兴趣,也欢迎告诉我们。
相关文章


 Altman
Altman

 Kardashian
Kardashian







