 2024-04-26 14:43
2024-04-26 14:43
苹果的AI野心揭露!发布首个小尺寸开源大模型OpenELM,从2.7亿到30亿四个规格代码全开源
以下文章节选自丨钛媒体
在上周,苹果公司突然公布了一则大新闻——
北京时间4月25日凌晨,苹果在 Hugging Face 平台上发布一个“具有开源训练和推理框架的高效语言模型”,名为OpenELM。

据了解,OpenELM有四种尺寸:2.7亿、4.5亿、11亿和30亿个参数版本,定位于超小规模模型,而微软Phi-3模型为38亿。这种小模型运行成本更低,可在手机和笔记本电脑等设备上运行。
同时,在WWDC24开发者大会之前,苹果彻底开源了OpenELM模型权重和推理代码,数据集和训练日志等。而且,苹果还开源了神经网络库CoreNet。

早在今年2月,苹果公司CEO蒂姆·库克就表示,苹果生成式 AI 功能将于“今年晚些时候”推出,有消息称即将在6月发布iOS 18可能是苹果iOS史上“最大”的更新,而9月也将推出首款AI加持的iPhone设备。
如今,苹果似乎在新一轮AI浪潮快到尾声的时刻追赶上了行业脚步。
开源代码:https://github.com/apple/corenet
在线体验:https://huggingface.co/apple/OpenELM
论文研究:https://arxiv.org/abs/2404.14619
据了解,本次发布的苹果开源大模型OpenELM,预训练Tokens数量相比于此前开源社区发布的OLMo模型减少了一半,仅有11亿的数据集参数规模,但是苹果模型性能效果甚至比竞品更精准。
随着ChatGPT风靡全球,近几个月来,三星、谷歌、小米等手机厂商全面推进大语言模型在手机、平板等端侧上的使用,包括照片处理、文字处理增强等,并形成一大卖点。而苹果很少透露并极少有类似的自带功能,主要是用第三方工具做到类似效果。
今年2月财报会议上,库克首次公布生成式 AI 计划,并将在今年晚些时候将 AI 技术集成到其软件平台(iOS、iPadOS 和 macOS)中。
库克表示:
我只想说,我认为苹果在生成式 AI 和 AI 方面存在着巨大的机会,无需透露更多细节,也无需超出自己的预期。展望未来,我们将继续投资于这些和其他将塑造未来的技术。其中包括 AI,我们继续在 AI 领域花费大量时间和精力,我们很高兴能在今年晚些时候分享我们在该领域正在进行的工作的细节。我们对此非常兴奋。
实际上,自年初至今,苹果在生成式 AI 领域动作不断。今年3月,苹果技术团队发表论文《MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training》,首次披露苹果大模型MM1,涵盖300亿参数、支持多模态、支持MoE架构,超半数作者属于华人。
如今,针对手机、平板等端侧领域,苹果真正的开源模型终于来了。
据论文显示,苹果开源了大语言模型OpenELM,有指令微调和预训练两种模型版本,共有2.7亿、4.5亿、11亿和30亿4种参数,提供生成文本、代码、翻译、总结摘要等功能。虽然最小的参数只有2.7亿,但苹果使用了包括RefinedWeb、去重的PILE、RedPajama的子集和Dolma v1.6的子集在内的公共数据集,一共约1.8万亿tokens数据进行了预训练,这也是其能以小参数表现出超强性能的主要原因之一。
例如,11亿参数的OpenELM,比12亿参数的OLMo模型的准确率高出2.36%,而使用的预训练数据却只有OLMo的一半。
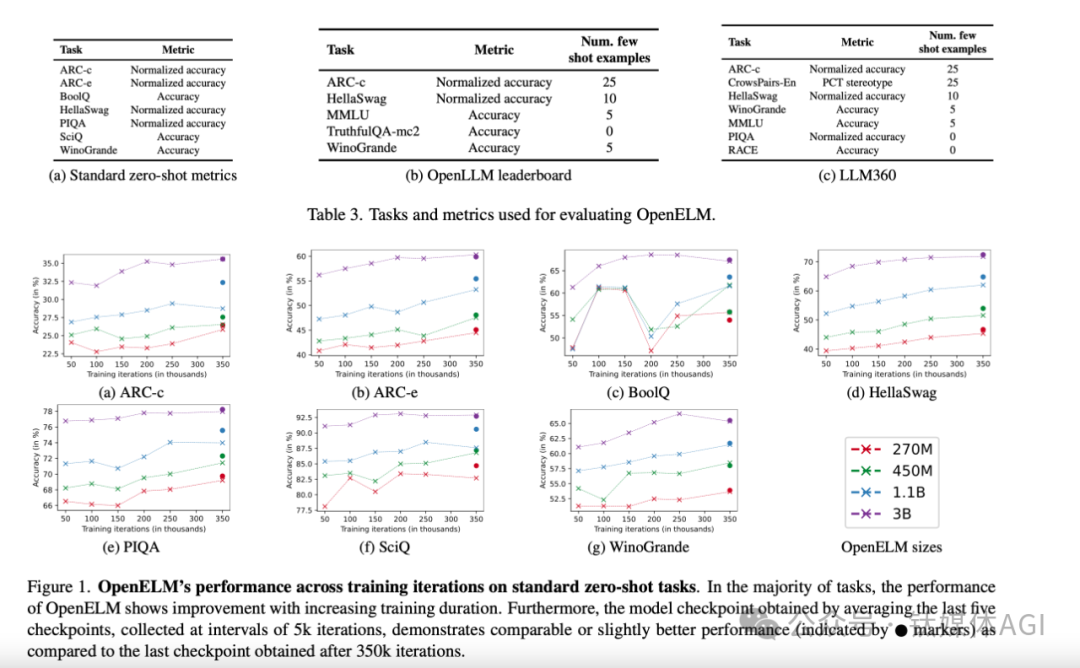
在训练流程中,苹果采用了CoreNet作为训练框架,并使用了Adam优化算法进行了35万次迭代训练。而苹果的MobileOne、CVNets、MobileViT、FastVit等知名研究都是基于CoreNet完成的。
苹果在论文中还表示,与以往只提供模型权重和推理代码并在私有数据集上进行预训练的做法不同,苹果发布的版本包含了在公开数据集上训练和评估语言模型的完整框架,包括训练日志、多个检查点和预训练配置。同时,苹果还发布将模型转换为 MLX 库的代码,以便在苹果设备上进行推理和微调。
“此次全面发布旨在增强和巩固开放研究社区,为未来的开放研究工作铺平道路。”苹果研究团队表示。
此外,OpenELM不使用任何全连接层中的可学习偏置参数,采用RMSNorm进行预归一化,并使用旋转位置嵌入编码位置信息。OpenELM还通过分组查询注意力代替多头注意力,用SwiGLU FFN替换了传统的前馈网络,并使用了Flash注意力来计算缩放点积注意力,能以更少的资源来进行训练和推理。同,苹果使用了动态分词和数据过滤的方法,实现了实时过滤和分词,从而简化了实验流程并提高了灵活性。还使用了与Meta的Llama相同的分词器,以确保实验的一致性。
这次,苹果很有诚意将代码开源,一开到底,把所有内容都贡献出来了。仅1天多的时间,该模型GitHub平台上就获得超过1100颗星。
而目前,大模型领域主要分为开源和闭源两大阵营,国内外知名闭源的代表企业有OpenAI、Anthropic、谷歌、Midjourney、百度、出门问问等;开源阵营有Meta、微软、谷歌、商汤、百川智能、零一万物等。
苹果作为手机闭源领域的领导者,此次却罕见地加入开源大模型阵营。有分析认为,这可能在效仿谷歌的方式先通过开源拉拢用户,再用闭源产品去实现商业化营利。
同时,这也表明苹果进军 AI 大模型领域的坚定决心。
相关文章


 Altman
Altman








