 2024-02-07 18:19
2024-02-07 18:19
阿里发力持续加码,通义千问再开源:Qwen V1.5版本提供六种参数版本,性能彻底碾压GPT-3.5
AI奇点网2月7日报道丨春节前后,内卷依旧。赶在春节前,阿里人工智能实验室打造的通义千问大模型(Qwen)的 V1.5 版上线了。新版大模型包括六个型号尺寸:0.5B、1.8B、4B、7B、14B 和 72B,其中最强版本的性能超越了GPT-3.5、Mistral-Medium,包括 Base 模型和 Chat 模型,且有多语言支持。

通义千问团队表示,相关技术也已经上线到了通义千问官网和通义千问 App。
除此以外,Qwen V1.5还支持 32K 上下文长度;开放了 Base + Chat 模型的检查点;可与 Transformers 一起本地运行;同时发布了 GPTQ Int-4 / Int8、AWQ 和 GGUF 权重。
借助更先进的大模型作为评委,通义千问团队在两个广泛使用的基准 MT-Bench 和 Alpaca-Eval 上对 Qwen1.5 进行了初步评估,评估结果如下:
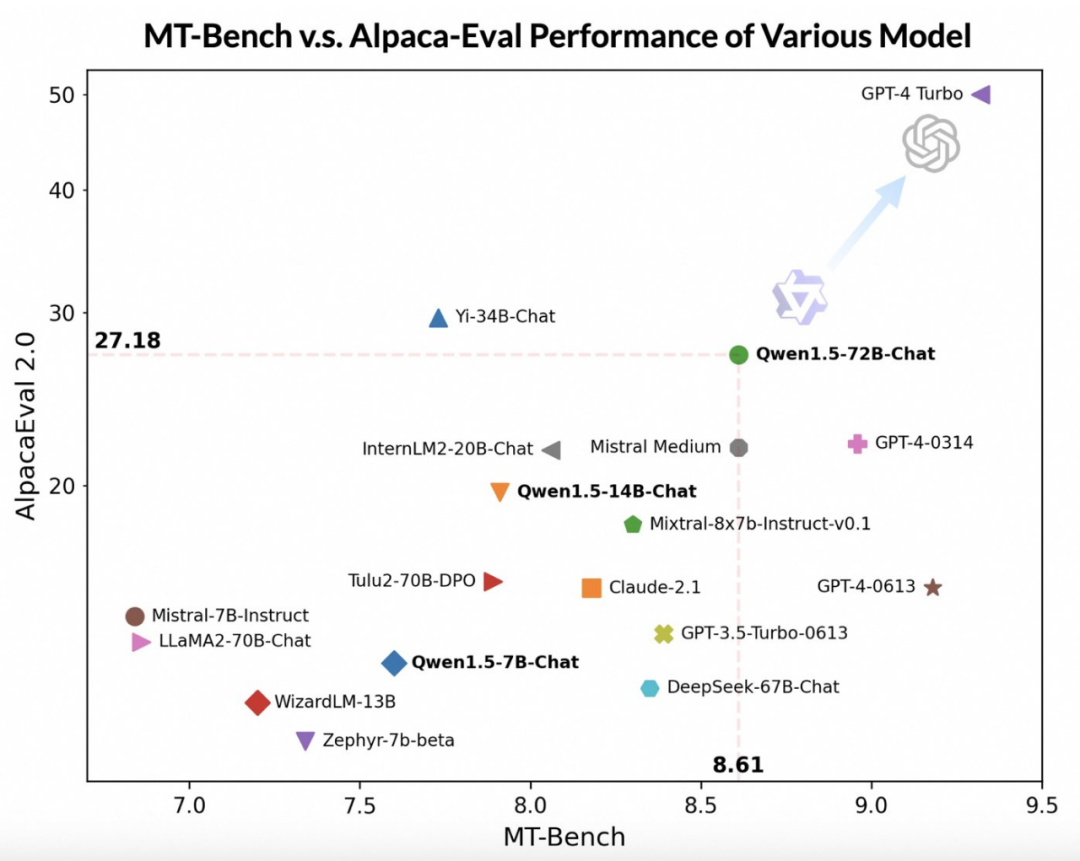
尽管落后于 GPT-4-Turbo,但最大版本的 Qwen V1.5 模型 Qwen1.5-72B-Chat 在 MT-Bench 和 Alpaca-Eval v2 上都表现出了可观的效果,性能超过 Claude-2.1、GPT-3.5-Turbo-0613、Mixtral-8x7b-instruct 和 TULU 2 DPO 70B,与最近热门的新模型 Mistral Medium 不相上下。
此外通义千问团队表示,虽然大模型判断的评分似乎与回答的长度有关,但人类观察结果表明 Qwen1.5 并没有因为产生过长的回答来影响评分。AlpacaEval 2.0 上 Qwen1.5-Chat 的平均长度为 1618.与 GPT-4 的长度一致,比 GPT-4-Turbo 短。
通义千问的开发者表示,最近几个月,他们一直在专注探索如何构建一个真正「卓越」的模型,并在此过程中不断提升开发者的使用体验。
相较于以往版本,本次更新着重提升了 Chat 模型与人类偏好的对齐程度,并且显著增强了模型的多语言处理能力。在序列长度方面,所有规模模型均已实现 32768 个 tokens 的上下文长度范围支持。同时,预训练 Base 模型的质量也有关键优化,有望在微调过程中为人们带来更佳体验。
关于模型基础能力的评测,通义千问团队在 MMLU(5-shot)、C-Eval、Humaneval、GS8K、BBH 等基准数据集上对 Qwen1.5 进行了评估。
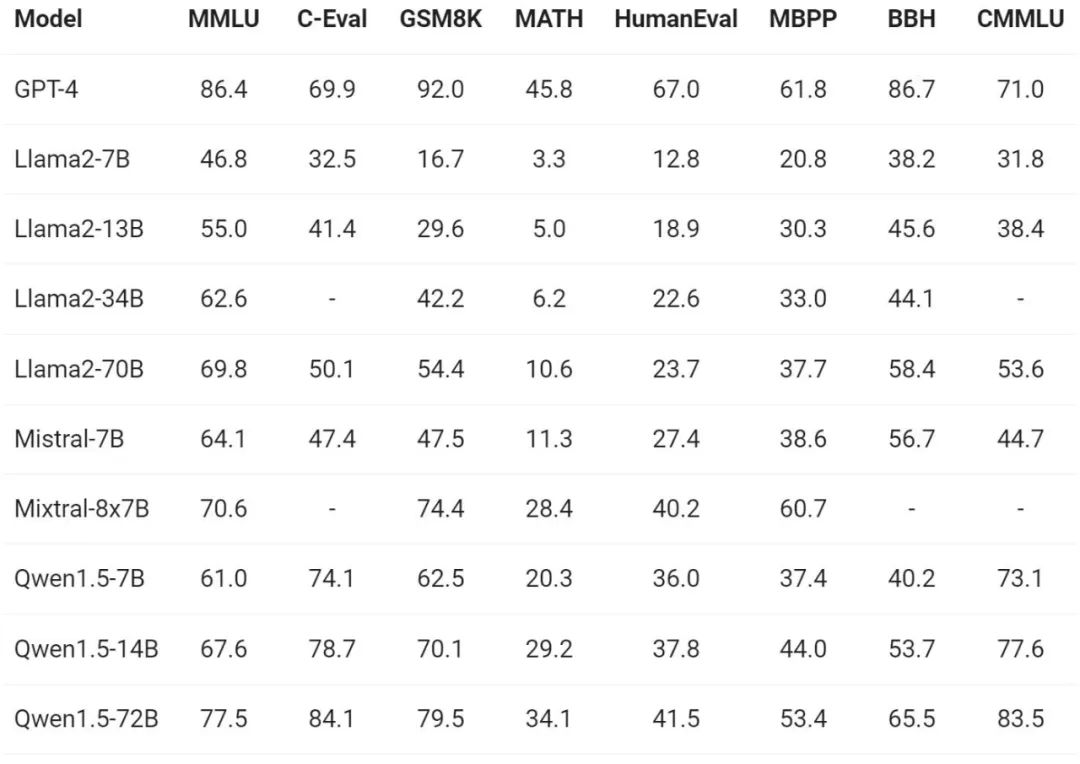
在不同模型尺寸下,Qwen1.5 都在评估基准中表现出强大的性能,72B 的版本在所有基准测试中都超越了 Llama2-70B,展示了其在语言理解、推理和数学方面的能力。
GitHub项目地址:
相关文章


 Kardashian
Kardashian


 Altman
Altman






