 2024-01-04 14:42
2024-01-04 14:42
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
家人们,火爆全球的魔性舞蹈《科目三》,谁能料到,就连兵马俑士兵也开始跳上了?!

热度还居高不下,被轰上了热搜,小伙伴们纷纷惊掉了下巴表示“闻所未闻,见所未见”。

这到底是怎么一回事?
原来,是有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
许多普通用户可能还不熟悉,但技术圈的盆友对这个技术肯定不陌生,出道至今1个月时间,这个项目便已经在GitHub上斩获了超1.1万个⭐️⭐️。
呼唤它能让更多人轻松上手体验的声音,也越来越多。

好消息是,现在「Animate Anyone」已经可以免费体验了!
而且“入口”还直接被嵌进了阿里的通义千问APP——名曰:通义舞王。
很快,各种效果、各种玩法、各种人物,都动了起来……例如让近期热播历史传记电影的主角拿破仑表演了一把……

这标致的舞姿,这反差的形象,着实算是把脑洞给打开了。
也有不少网友换了个思路:想用自己照片试试,以后投B站舞蹈区的宅舞视频可以直接生成。
效果究竟行不行,我们也忍不住实测了一波~
打开通义千问APP,我们只需要点击对话框中的“一张照片来跳舞”:
或者在输入框内敲“通义舞王”或“全民舞王”等关键词,就可以跳转到相应界面了:
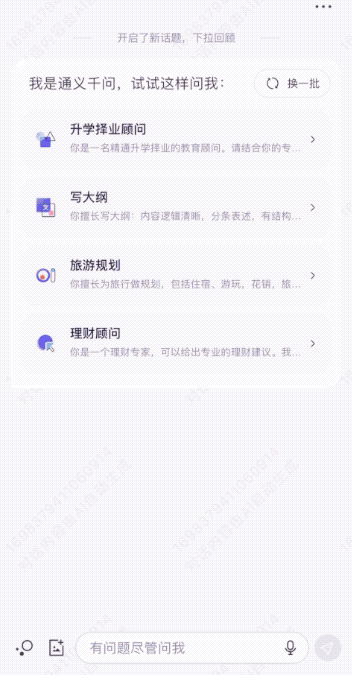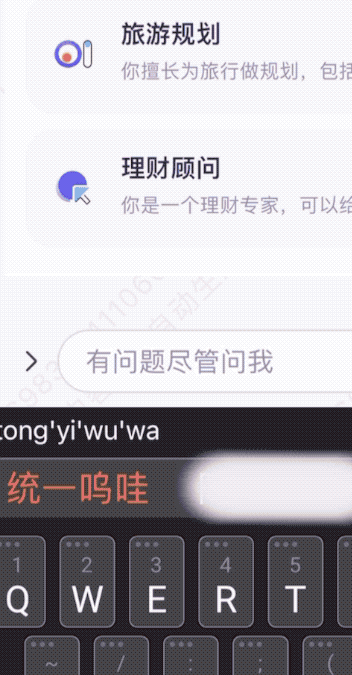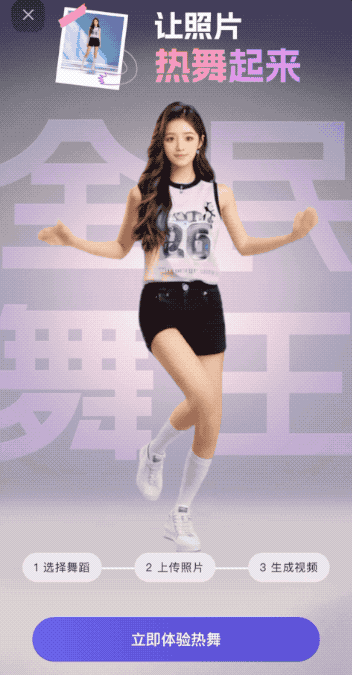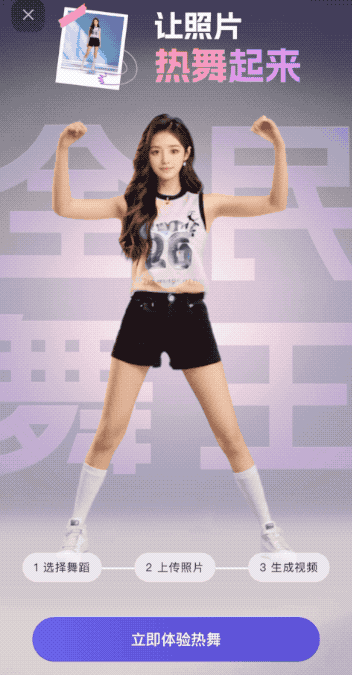
接下来的操作,也正如我们刚才所说:极、其、简、单。
首先,在众多已经提供的模板中,pick一个。

目前通义千问APP提供了12个舞蹈模板,这次我们就选择二次元最爱的宅舞《极乐净土》测试一下~
然后,选一位测试对象。比如我们找了亚马逊的创始人兼CEO贝佐斯:

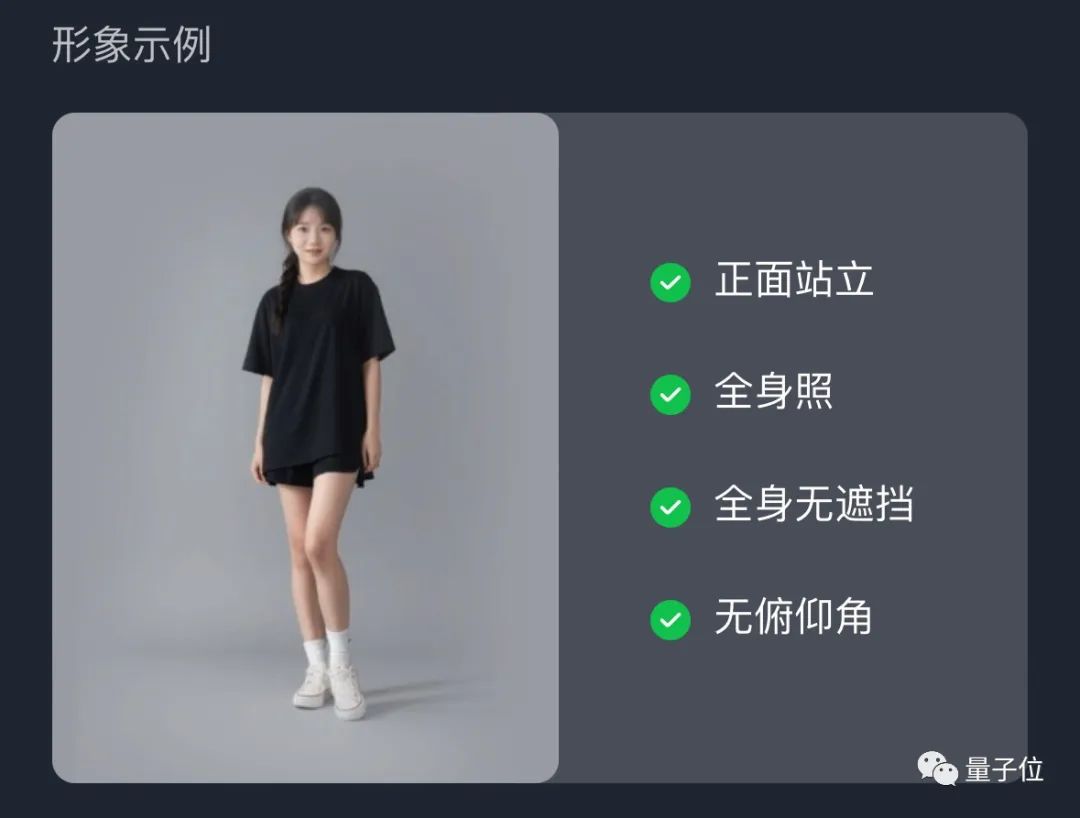
需要说明的是,在选择照片的时候,还是需要一点“技巧”的,“通义舞王”也有相应提示:
在此之后,直接点击“立即生成”,静候几分钟,贝佐斯大跳《极乐净土》的视频,就诞生了:

是不是效果还行?虽然还不能讲“真假难辨”,但能让贝老板为你跳一曲了,还要什么自行车。
不仅如此,“通义舞王”除了能够生成真人风格之外,还有其他风格可玩。
例如动漫风格的小姐姐跳DJ慢摇:

还有卡通风格的人物热舞:

总而言之,现在你想让任何人物角色跳舞——只需要一张人物的全身照就够了。
不过有一说一,虽然“通义舞王”已经成功吸引了众多网友前来玩耍,反响火爆,但它也还没到完美无瑕的境界。
例如等待生成的时长,现在平均时间最起码都得10分钟以上,但免费的话还要啥自行车呢?还有就是,从视频效果来看,如果照片角度不好或者清晰度不够也会影响AI对于人物手部的处理。

这些问题,实际都与背后的技术原理和技术挑战,密不可分。
在视觉生成任务中,目前较为主流的方法便是扩散模型。
但在仅靠一张照片就生成视频这件事上,它还面临着诸多的挑战,例如人物形象一致性(Consistency)的问题。简单来说,就是如何保证照片人物在动起来的过程中,各种细节能够和原照片保持一致。
为此,阿里团队在扩散模型的基础之上,提出了一个新的算法,也就是我们刚才提到的「Animate Anyone」。从一致性、可控性和稳定性三个方面,保证了视频输出的效果和质量。
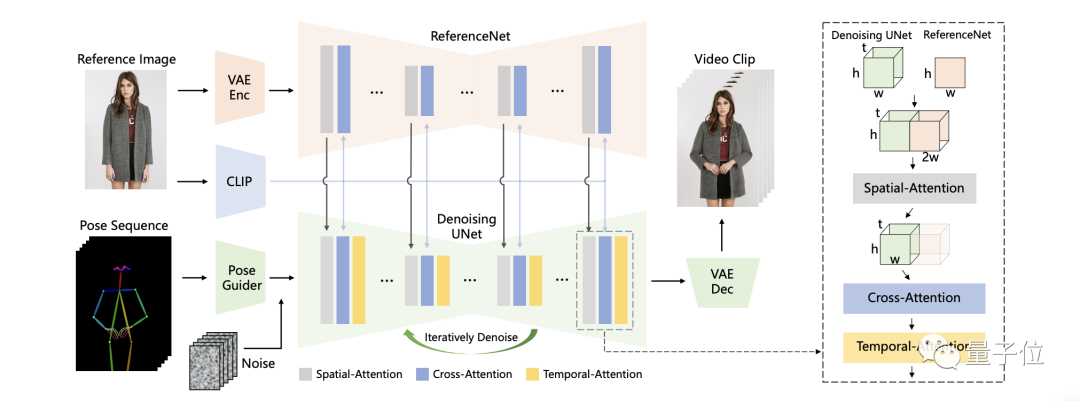
例如,在一致性方面,阿里团队引入的是ReferenceNet,用于捕捉和保留原图像信息,可高度还原人物、表情及服装细节。
具体而言,在参考图特征提取上,ReferenceNet采用的是与去噪UNet类似的框架,但没有包含时间层;它继承了原始扩散模型的权重,并独立进行权重更新。
在将ReferenceNet的特征融合到去噪UNet时,首先将来自ReferenceNet的特征图x2复制t次,并与去噪UNet的特征图x1沿w维度连接;然后进行自注意力处理,并提取特征图的前半部分作为输出。
虽然ReferenceNet引入了与去噪UNet相当数量的参数,但在基于扩散的视频生成中,所有视频帧都需要多次去噪,而ReferenceNet只需在整个过程中提取一次特征,因此在推理过程中不会导致显著增加计算开销。
在可控性方面,阿里团队使用的是Pose Guider姿态引导器。Pose Guider姿势引导器采用的是一个轻量级设计,而不是引入一个额外的控制网络。
具体来说,使用了四个卷积层(卷积核大小为4×4,步幅为2×2,通道数分别为16、32、64、128),这些卷积层用于将姿势图像对齐到与噪声潜变量相同的分辨率。
处理后的姿势图像会被加到噪声潜变量上,然后一起输入到去噪UNet中,从而在不显著增加计算复杂性的情况下,为去噪UNet提供姿势控制。
最后是在稳定性方面,阿里团队引入的是一个时序生成模块。
时序层的设计灵感来源于AnimateDiff,通过在特征图上执行时间维度的自注意力,以及通过残差连接,其特征被整合到原始特征中。
同样的,这个模块的作用之下,满足了在保持时间连续性和细节平滑性的同时,减少了对复杂运动建模的需求。
最终,在「Animate Anyone」的加持之下,从效果上来看,保证了图像与视频中人物的一致性。

这也是「Animate Anyone」背后的技术原理。然而,阿里之所以不断在「Animate Anyone」上攻坚优化,并非完全出于技术很酷很有潜力,还藏着一颗引领视频生成技术的野心。
因为大家都在问「What is the Next」的时候,大型视觉模型LVM(Large Vision Model)已经潮水声轰鸣了。
实际上,在「Animate Anyone」火了之后,阿里还有另一项视频生成技术在同时出圈。这个项目叫「DreaMoving」,只需一张脸部照片、一句话描述,就能根据提示词指示,让你生成在任何场景下进行跳舞!
例如:下面这段《擦玻璃》的舞蹈视频:

感兴趣的朋友可以点击下方卡片,阅读此前的介绍文章:
相关文章
近期文章
更多


 Kardashian
Kardashian


 Altman
Altman






