 2023-11-10 17:09
2023-11-10 17:09
国产大模型轮番碾压ChatGPT?AI大模型跑分“作弊”的事,终于有人说出真相

11月6日,伴随OpenAI庆祝ChatGPT上线一周年暨开发者大会,我们迈过了「AI元年」。今年层出不穷的AIGC工具和软件,让大家的工作效率提升了不止一点点。
上半年,大模型满天飞,下半年,应用纷纷落地。但凡稍微大一点的互联网公司,没有推出“自研大模型”,创始人名字都得倒着写。
最近,手机厂商和芯片大厂纷纷进场打榜,发布会一开,个个都是「跨越式突破」,每家都是「排行第一」。要么是打破了Benchmark测评基准的历史记录;要么是在前边加若干前缀,比如实现了「×亿内」参数量的第一名。
在这里,EVA就不点名了。

在兴奋于技术进展迅速之余,有一些人发现了一点异常——
EVA曾经将“AI大模型打榜”这种行为誉为「不服跑个分3.0时代」。
关注手机圈的家人们,都经历过“娱乐兔”和DxOMark这两个「跑分大战」的阶段。
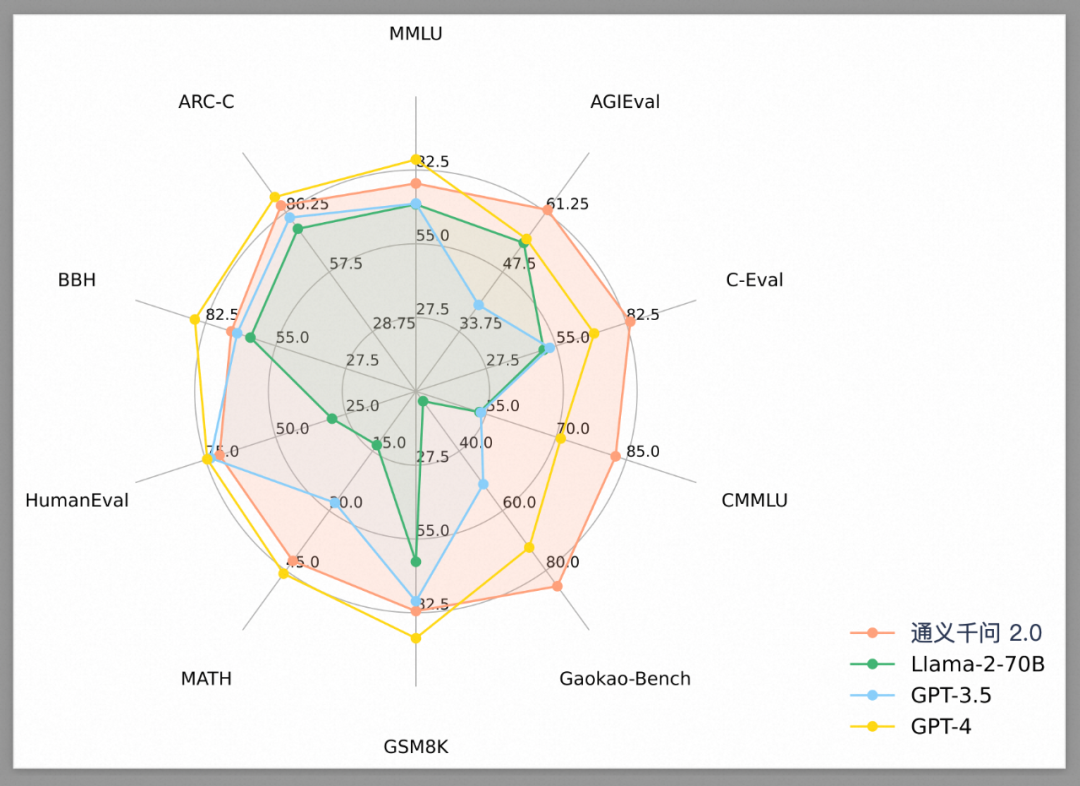
越来越多人开始发出疑问,语言模型测评Benchmark这种东西,到底靠不靠谱?
直到近日,知乎上有一个帖子引起了大家的广泛关注。
文章标题是:《如何评价天工大模型技术报告中指出很多大模型用领域内数据刷榜的现象?》
是的,就是所谓的“大模型刷榜”。但凡经历过一些电商圈毒打的家人,都应该听说过“刷评”“刷赞”这种行为。
如果将AI转为人类的角度理解,已知消费者对商品评价敏感,商家发动几百个人,为自己的商品进行不同方式的“刷榜”,最终营造一个非常卓越的靓丽评论区与舆情环境。
我们绕回来,国内AI模型公司昆仑万维的「天工」大模型团队,在上个月发布了一篇技术论文。

论文当中,揭开了多家大模型“刷榜”的机制。
论文本身,其实是介绍天工的自研大模型Skywork-13B。
按照惯例,新诞生的大模型需要解释自己的研究方法,作者表示在流行的语言模型测评基准上,他们的模型在很多中文的分支任务上取得了“业内最佳”。此外,他们还引入了一种新的测评方法——与测评题目的“标准答案”进行查重。
有趣的是,这篇论文还利用同样的机制验证了许多主流大模型的真实效果,指出了一些很有名气的开源国产大模型存在“投机取巧”的嫌疑。
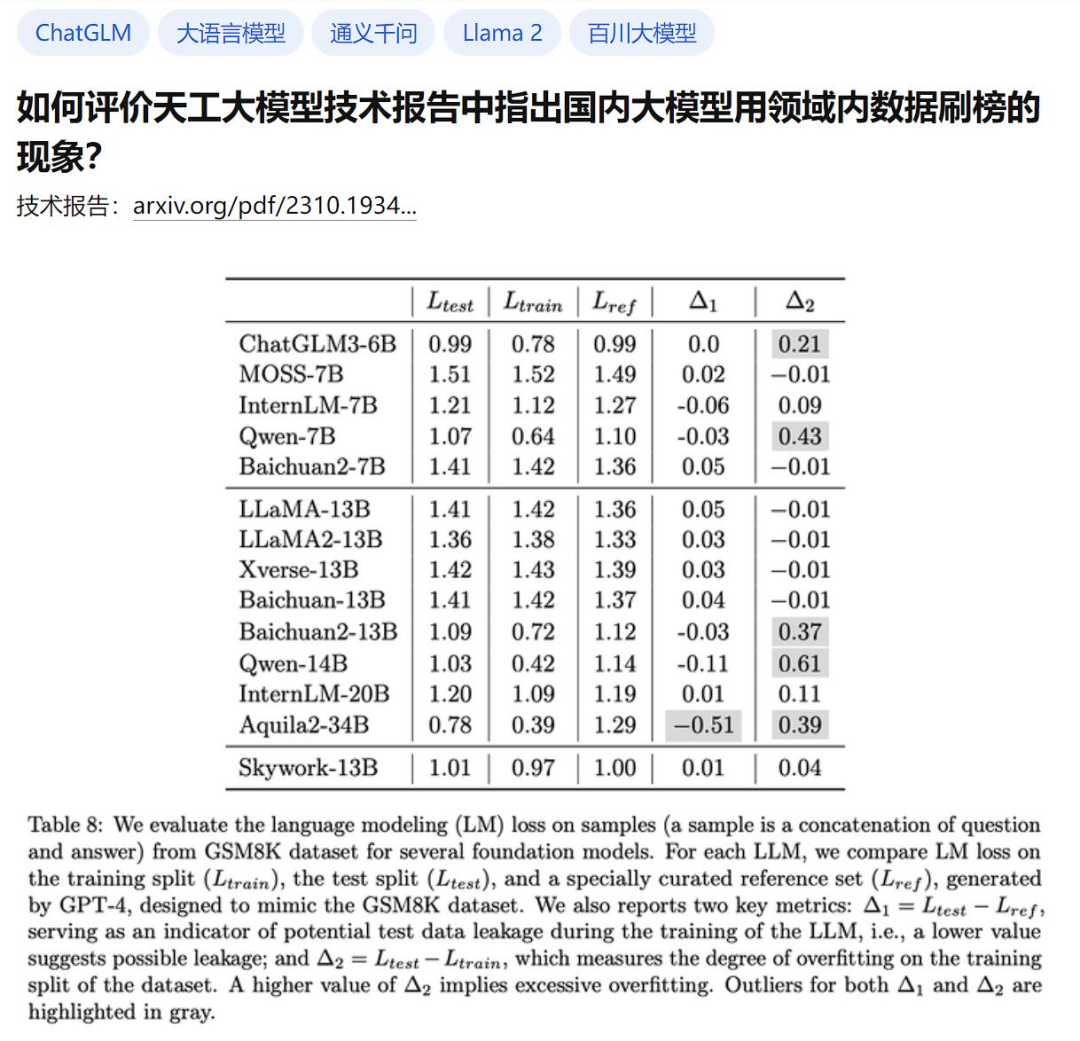
我们来看论文里边的这个表格:
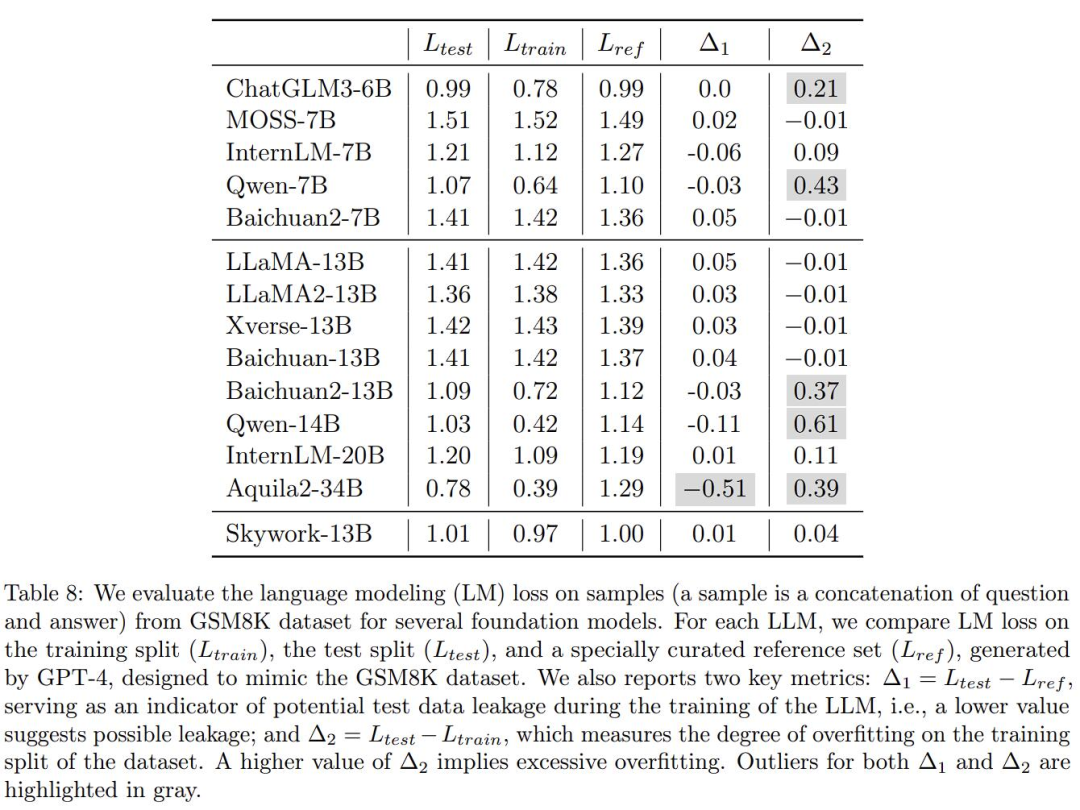
这里边有几家模型,大家多少都有所耳闻。比如:智谱AI的ChatGLM、百川的Baichuan 2、复旦的MOSS、Meta的LLaMa……
论文作者在训练大模型的时候使用了一种检验机制,为了验证业内几个知名大模型回答数学问题的答案相似度,他先使用GPT-4生成了答案样本,人工核对了回答的正确性,并且让其他的模型也对这些题目生成回答。
作者将数学题册的训练集问题与答案,与大模型们生成的答案进行比对,用统计学的方法,计算里边的逐字逐句与GPT-4答案以及数学题训练集的吻合率。
结果他得到了一个“惊人的结论”——如果大模型没有用测试集进行针对性训练,那么吻合率的数值应该趋于零。

翻译过来的“大白话”就是:
如果有的大模型在训练时,提前拿着Benchmark基准测试的题目和答案作为“学习资料”,想借由此来刷高分,那么统计学出来的数字就会发生异常。
好的,都是哪些模型有异常呢❓
在上边的表格里,作者已经用灰色特意圈出来了。
换而言之,如果你在期末考之前,提前拿着考试题答案进行复习和背诵,然后上考场应试,那么因为回忆+赶时间,你写出来的答案理论上会十分接近于“官方答案”。这就好比大模型在训练时就进行了一轮又一轮针对Benchmark“完美押题”的开卷考试,强迫“记忆”。
我再举一个比较老生常谈的例子:
已知物理低温下CPU的性能可以更好地释放,于是乎,大家都把手机放进冰箱进行跑分。这里还不包括提前针对Benchmark软件的预设程序进行“专属优化”。?

EVA需要强调的是,这种论证机制仍不足以证明大模型在训练时候存在“押题”或者“造假”。
此外,让AI大模型按照开发商想要的方向进行回答,也不止这一种方法。
EVA就曾遇到过,聊天机器人在回答到一半的时候,忽然换了一个回复。
这就能解释,为什么会有许多家人在看完某场模型发布会,然后自己亲身体验后,感觉似乎跟官方宣传的不是那么一回事儿?
事实上,针对新发布大模型进行“刷榜”,往往有其个中无奈的商业逻辑——需要对投资人的期望给予足够的正向反馈,或者面对用户时展示自己的技术实力。
看完知乎全文,有网友对此评论道:终于有人敢将“内幕”公之于众了。
还有网友表示:大模型的智力水平,最好的办法就是盲训(zero-shot)和挑战一些几乎不可能出现在测试集的题目。

智商不够的EVA仔细想了一下,某“高智商贴吧”似乎又占领了高地??
一位答主在知乎上回复称,他希望让大家理性看待“刷榜”这个事情,事实上很多模型和GPT-4的差距还很大。
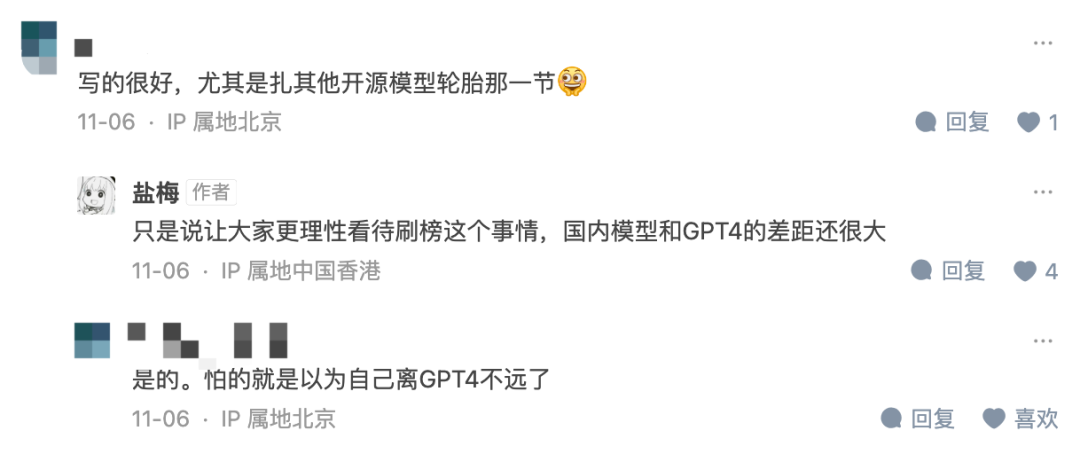
这一点,360创始人周鸿祎曾经在今年5月初,某家大模型公司开完发布会之后,发表过类似的观点。
他说:“不经过两年模仿期就说「超越」GPT,那叫「吹牛」。”
相关文章
近期文章
更多

 Altman
Altman







