 2023-06-06 13:40
2023-06-06 13:40
腾讯AI实验室联合剑桥大学推出大语言模型PandaGPT:支持文本图像音频等跨模态能力
AI奇点网6月6日报道丨6月2日,来自英国剑桥大学、日本奈良先端科学技术大学院大学、腾讯AI Lab的多位研究人员们在网上公开发布了通用指令跟随大模型PandaGPT(直译过来就是:熊猫GPT)。

据介绍,PandaGPT可以执行复杂的任务,如生成详细的图像描述、编写受视频启发的故事、回答有关音频的问题。PandaGPT可同时接受多模态输入,并自然地组合它们的语义。
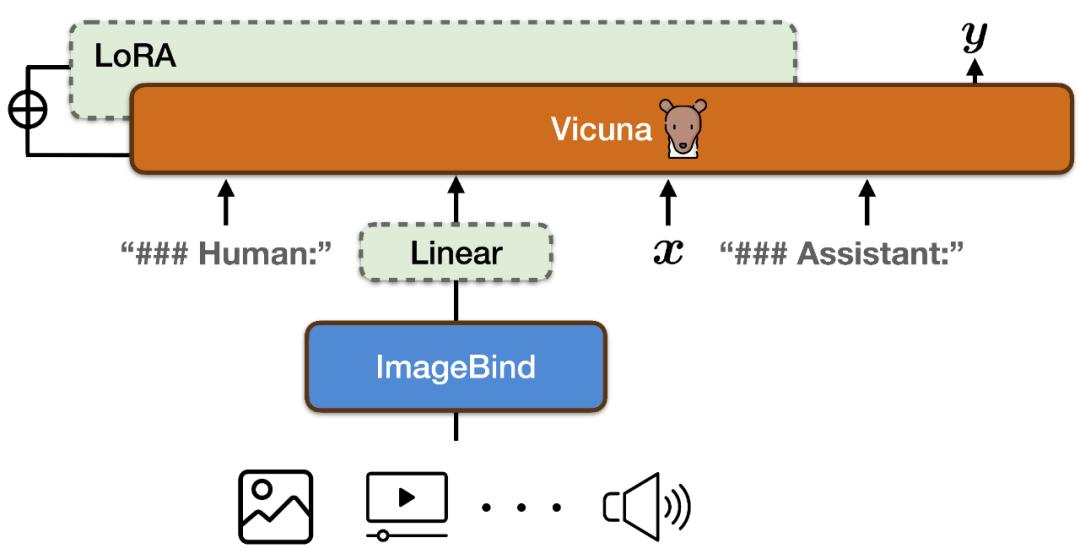
PandaGPT在文本、图像/视频、音频、深度、热度(thermal)和IMU六种模态上展示了跨模态能力,但由于ImageBind提供的共享嵌入空间,它只能使用对齐的图像-文本对进行训练。研究人员希望PandaGPT可以作为构建通用人工智能(AGI)的第一步,它可以像人类一样全面地感知和理解不同形式的输入。
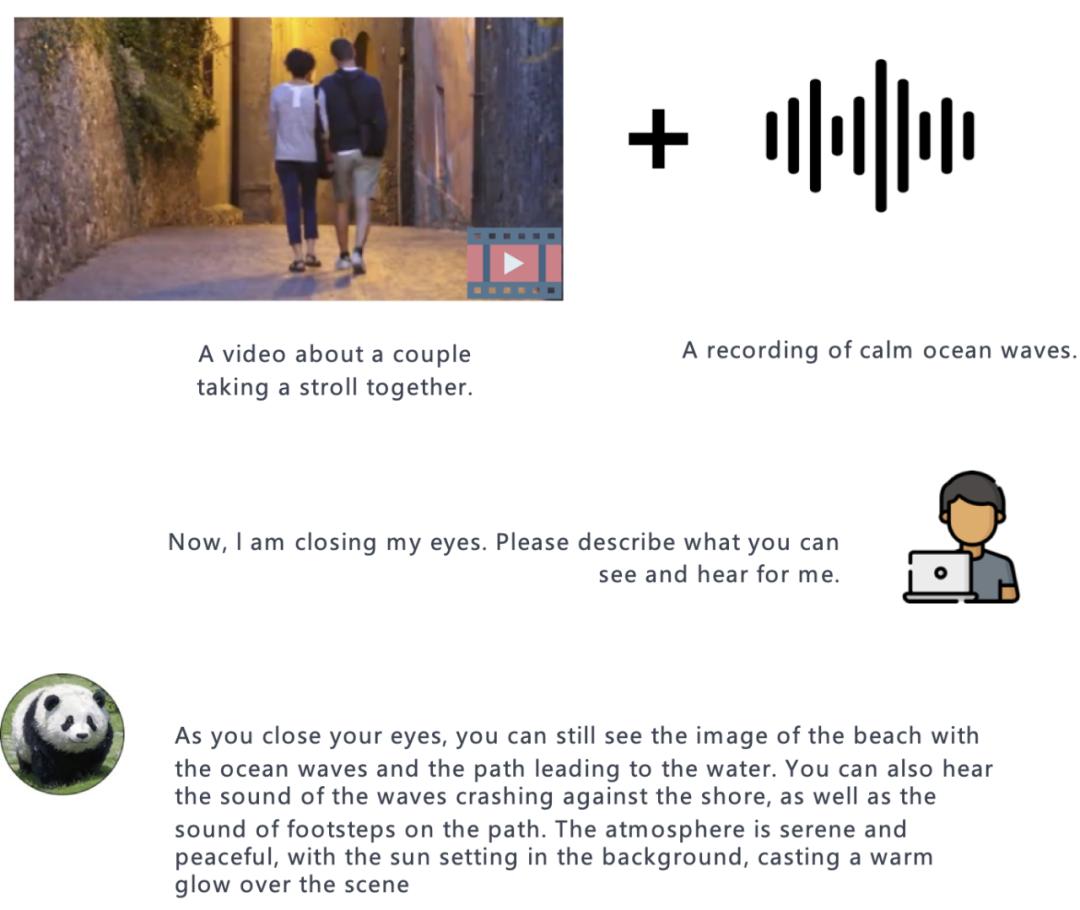
值得强调的是,目前的 PandaGPT 版本只使用了对齐的图像 - 文本数据进行训练,但是继承了 ImageBind 编码器的六种模态理解能力,具备在所有模态之间跨模态能力。在实验中,论文作者展示了 PandaGPT 对不同模态的理解能力,包括基于图像 / 视频的问答,基于图像 / 视频的创意写作,基于视觉和听觉信息的推理等等,下面其中一个例子,PandaGPT可以很好的接合图像+音频来判断一个事物:
论文作者在最后总结了目前 PandaGPT 的诸多问题以及未来的发展方向。他们认为,PandaGPT还不足以走完商用前的准备阶段。
尽管 PandaGPT 在处理多种模态及其组合方面具有惊人的能力,但仍有多种方法可以极大程度的提升其性能。PandaGPT 可以通过使用其他模态对齐数据来进一步提升图像以外模态的理解能力,例如利用 ASR 和 TTS 数据来进行音频 - 文本模态的模态理解和指令跟随能力。
文本以外的其他模态仅仅使用了一个 embedding 向量进行表示,导致语言模型无法理解文本之外模型的细粒度信息。更多关于细粒度特征提取的研究,如跨模态注意力机制,可能有助于提高性能。 PandaGPT 目前仅允许将文本之外的模态信息用作输入。未来该模型有潜力将整个 AIGC 统一到同一个模型之中,即一个模型同时完成图像 & 视频生成、语音合成、文本生成等任务。
此外,PandaGPT 还可能表现出现有语言模型的一些常见缺陷,包括辨识幻觉、毒性和刻板印象。最后,官方认为,PandaGPT 仅仅是一个研究项目,暂时还不足以应用于生产环境。
相关文章
近期文章
更多

 Altman
Altman

 Kardashian
Kardashian






