 2023-09-10 11:32
2023-09-10 11:32
通俗易懂!十分钟搞懂 Stable Diffusion的基础概念,小白也能用AI绘画
大家好,我是每天分享AI应用的萤火君!
今天给大家介绍下 Stable Diffusion 的一些基础概念。
所谓磨刀不误砍柴工,只有把刀磨锋利了,砍起柴来才能得心应手,才能顺利的砍到所需的柴火。砍柴如此,平常做事情也是这样,我们要做好一件事,首先就要打好基础,找出核心的方面,搞懂相关原理,理清楚其中的利害关系,然后才能加以利用,进而得到满意的结果。
我是6月份开始接触 Stable Diffusion 的,当时参加了一个社区,有老师专门教AI绘画,然后我就按照教程一步一步的做,最后出图的时候特别有成就感,那个感觉就像掌控了整个世界,也有点类似于刚拿到汽车驾照的感觉。
但是,跟着别人做的时候很顺利,按照自己的想法绘图时就遇到很多问题,经常搞很久都不能得到满意的结果,各种参数调来调去,一遍遍的生成,花费很多的时间,也拿不到想要的结果,如果电脑有感情,可能都要崩溃了。
后来我意识到,不能再这样搞下去了,这样搞下去成不了专家(哈哈)。我之所以很难拿到结果,是因为我对 Stable Diffusion 的认识太简单太肤浅,很多参数都是一知半解,很多时候都是按照自己想当然的方法各种乱试,没有抓住要领,没有搞懂原理,这样就很难用好这个工具,我操之过急了。
然后我开始详细了解 Stable Diffusion 的各种概念,尽量去理解相关的原理,去查询各个参数的作用,然后再去实践,遇到搞不清楚的地方,再去搜索查询,如此反复,终于搞明白了一些事情,也能生成一些想要的图片了。因为我这些认识也是从别人那里学来的,本着人人为我,我为人人的精神,我也把自己学到的一些东西分享出来。
本文就和大家分享一下我了解到的一些 Stable Diffusion 的基础概念,相关说明在保持基本正确的情况下会尽量通俗易懂,希望能帮助到身处困惑中的同学。
模型
理解模型这个词需要一点初中数学知识,可以把每个模型看成一个数学函数:y=f(x),输入参数 x,得到返回值 y。只不过这个函数可能特别复杂,里边会有很多的子函数,这些子函数通过各种规则进行连接。
在使用 Stable Diffusion 生成图片时,我们会遇到很多的模型,最基础的就是 Stable Diffusion 大模型,比如Anything、realisticVision等等,对于此类模型,我们可以简单的认为模型的参数就是提示词、图片尺寸、提示词引导系数、随机数种子等等,返回值就是图片数据。
除了大模型,平常使用较多的还有 Lora 模型、嵌入式模型。Lora 模型是一种微调模型,可以用来生成某种特色图片,比如一些机甲、插画风格的模型。嵌入式模型通常使用单个输入代表一组数据,从而可以节省一些配置,比如常用的负面提示词模型 EasyNegative。
除了 Stable Diffusion 自身支持的模型,很多插件也需要模型才能正常运行,比如ADetailer,就需要下载修脸、修手的模型。
模型文件的后缀名有很多种,比如常用的 Stable Diffusion 大模型文件名后缀一般是 .safetensors 和 .ckpt,.safetensors 文件比 .ckpt 文件更安全和快速,有这个的时候推荐用这个。还有一些模型的后缀名是 .pt、.pth、.onnx等等,它们一般由不同的机器学习框架训练而来,或者是包含的信息格式存在差异。
Stable Diffusion
Stable Diffusion 是一种很先进的生成技术,集算法与模型为一身,2002年8月由 Stability AI 开源。Stable Diffusion 有时候会被简称为SD。
先来认识下这两个单词:
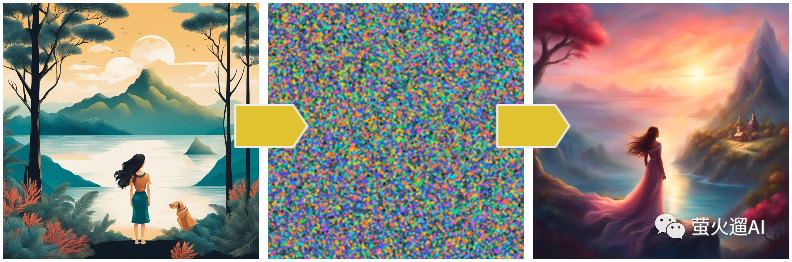
Diffusion 本意指的是分子从高浓度区域向低浓度区域的转移过程。Stable Diffusion 有两种扩散,前向扩散和后向扩散。
前向扩散就是向清晰的图片不断中增加噪音,让它变模糊,变成一张噪音图。这种噪音的分布需要符合自然图像的统计特性,使得图像的特征数据分布的更加广泛和均匀,从而能够增加生成图片的变化和多样性,更接近真实图像。
后向扩散描述的是从噪声图到清晰图的转化过程。随着扩散步骤的增加,噪声逐渐被去除,图像逐渐清晰。去噪就是去除不应该出现在画面中的像素点。
Stable 是稳定的意思,无论输入的文本提示词如何,经过训练的模型都可以稳定地生成符合文本提示词的图像,而且这些图像的质量通常是稳定的,不会出现明显的波动。
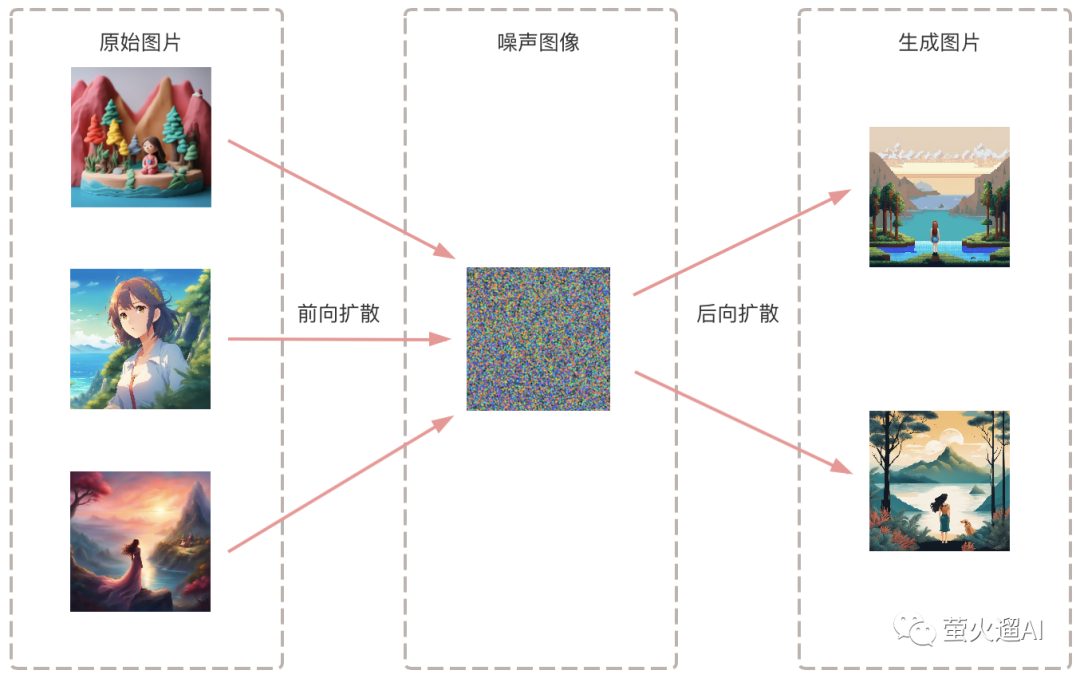
下面再介绍下 Stable Diffusion 的基本原理,分成两个方面:训练和生成。其核心就是在一个特殊的潜在空间中扩散。
潜在空间:Stable Diffusion 训练和生成图片并不是基于图片像素空间,而是在一个潜在空间中进行,这个潜在空间的维度比图片像素的维度要低很多,比如一个尺寸为 768*512 的图像,其像素维度为 768*512=393216.而 Stable Diffusion 模型的潜在空间维度通常在 768 维左右,可见潜在空间显著降低了对算力和显卡性能的要求,训练和生成图片的速度更快。
训练:指的是使用带有文本描述的图片构建生成模型的过程。
训练程序首先将文本描述通过一个编码器转换为潜在空间中的向量,文本描述向量的每一个维度都代表了文本描述的一个特征或者属性,例如颜色、形状、大小等。同时训练程序也会将原始图像转换到潜在空间中。
然后使用上面提到的“前向扩散”方法基于文本描述向量逐步生成噪声图像;
然后使用上面提到的“后向扩散”方法去除这个噪声图像中噪声,尽量恢复到原始图像的向量表示;
将得到的图片向量表示与原始图片的向量表示进行比对,计算损失值,然后调整模型的参数,以尽可能地减小损失。
这个过程重复多次,直到损失值无法再降低或者可降低的幅度非常小;同时文本描述转换的向量还会通过学习不断接近原始图片的信息。最终得到一个相对高质量的模型。
向量:就是具有大小和方向的量,比如加速度。向量还可以用来表示一组数值,例如图像的像素值、文本的单词频率等,使用向量可以方便地对数据进行操作和计算,比如通过计算两个文本向量之间的夹角得到它们的相似度。
生成:指的是模型使用者使用文本提示词+模型生成图片的过程。
生成时还是需要先将文本提示词转换为潜在空间中的向量。
然后使用“前向扩散”方法基于这个向量生成符合向量语义的噪声图像。
然后使用“后向扩散”方法去除这个噪声图像中的噪声,最终得到清晰的图片。
Stable Diffusion WebUI
一个最流行的开源 Stable Diffusion 整合程序,用户安装后可以直接通过 Web 页面使用 Stable Diffusion。
Stable Diffusion WebUI 的核心功能是 文生图 和 图生图,这两个功能也就是 Stable Diffusion 的核心能力。
Stable Diffusion WebUI 的其它功能,比如ControlNet、高清放大、模型训练等等都是其它第三方开发的,有的已经内置到 WebUI 中,随着 WebUI 的发布而发布,有的还需要用户手动安装。
除了Stable Diffusion WebUI,还有一些使用量比较大的整合程序:SD.Next、ComfyUI 等。
大模型
这里说的是 Stable Diffusion 大模型,有时也称为主模型、基础模型。Stability AI 官方发布了一个基础模型,但是因为比较通用,兼顾的方面比较多,特点不足,所以大家一般很少使用。比如有的人喜欢二次元、有的人喜欢真实、有的人喜欢3D,用官方模型出图的效果不是最优的,所以很多组织或者个人就专门训练某方面的模型,并发布到社区给大家使用。
同时因为大模型的训练成本很高,所以基本上没人会重头开始,这些模型一般基于 Stability AI 发布的官方模型二次训练而来。训练方法常见的有DreamBooth,DreamBooth模型可以将目标对象与新场景结合,生成创意新图片;训练这种模型可以只需要少量的目标对象的图片,也能达到较好的效果。
因为大模型训练时使用了大量的图片,累积了比较多的数据,所以模型文件很大,通常都在2G-7G。
对于 Stable Diffusion WebUI,大模型的安装默认目录是:\models\Stable-diffusion ,不过这个目录是可以通过启动参数更改的,注意确认你自己的大模型目录。
VAE
上面提到 Stable Diffusion 生成图片时会在一个潜在空间中进行处理,图片数据和潜在空间数据的转换就是由VAE模型处理的。VAE模型在这个转换过程中能够学习到一些图像特征的处理方式,使得生成的图像颜色更加鲜艳、细节更加锐利,可以用来解决图片发灰模糊的问题。
很多大模型会自带VAE模型,这时候我们就不需要再给它搭配一个VAE,当然也有不自带的,这时就需要搭配一个,在 Stable Diffusion WebUi 中可以无脑选择“自动识别”。
在秋叶整合包中提供了四个选项,如下图所示,我一般都选“自动识别”,除了 vae-ft-mse-840000-ema 比较通用,animevae 是专门优化二次元图片的。一般这两个VAE模型就够了。
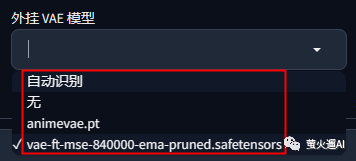
对于 Stable Diffusion WebUI,Vae 模型的安装默认目录是:\models\Vae ,注意替换 为你自己的安装目录。不过这个目录是可以通过启动参数更改的,注意确认你自己的 Lora 目录。
Lora
这是一种基于大模型的风格模型,也就是说它不能单独使用,必须配合一个大模型才行。比如我们画小姐姐的时候,可以用一些Lora模型来控制人物的服装、头饰;生成机械四肢的时候,可以用一些Lora模型来强化肢体上覆盖的机甲样式;画风景图的时候,可以用一些Lora模型来控制绘画的风格。
这种模型训练成本不高,往往只需要几十张图片就可以训练得到,比较方便普通用户试玩。
与 Lora 模型作用和使用方式类似的还有一种超网络模型,不过效果上较 Lora 模型差,社区中很少这种模型。
对于 Stable Diffusion WebUI,Lora 模型的安装默认目录是:\models\Lora ,初始状态下里边是空的,注意替换 为你自己的安装目录。不过这个目录是可以通过启动参数更改的,注意确认你自己的 Lora 目录。
提示词
对图像的描述,也就是想画一幅什么样的画。比如我上边使用的:a girl,但是这个提示词过于简单,AI虽然画出了一个女孩,但是他不知道你脑子里的女孩长什么样子,如果要画的更符合你的需求,你还要告诉他更多细节才好,比如女孩的头发是什么颜色、穿着什么衣服、站着还是坐着、在户外还是室内等等。
提示词在AI绘画中特别重要,一个常见的编写套路是:风格、主体、细节。风格就是图片是照片、水墨画,还是白描;主体就是你想画什么,比如1个女孩、1棵树、或者1条狗子;细节就是你的主体长什么样子,是长发还是短发,黑色头发还是粉色头发,眼睛是蓝色还是黄色等等。
另外我们还可以使用一些质量提示词提升图片的质量,比如: masterpiece、best quality、ultra-detailed、8K等,不过这对于新版的SDXL这些提示词没什么意义了,SDXL会努力做到最好;还有就是可以使用权重数字强化或弱化某个提示词对生成图片的影响,比如: red hair:1.31 ,这可以强化输出照片中头发颜色为红色的概率。
在 Stable Diffusion 中文本提示词会被转换为潜在空间中的向量,然后参考这个向量生成噪声图像,然后再对噪声图像进行采样去噪处理,逐步生成清晰的图像。
反向提示词
不想在图片中出现的东西,比如树、桌子、6根手指、缺胳膊断腿等等,在上边的示例中我使用了“EasyNegative”,这是一个嵌入式模型的代号,可以认为它代表了一些常见的反向提示词,使用它就不用一个个输入了,且只使用一个提示词的数量额度。
提示词引导系数

在 Stable Diffusion 中,提示词引导系数实际上影响的是噪声图像,通过调整该参数,可以改变噪声图像与原始文本的相关性。这个参数的值越小生成图像越自由,越大则更注重文本信息的影响。
采样器和采样步数
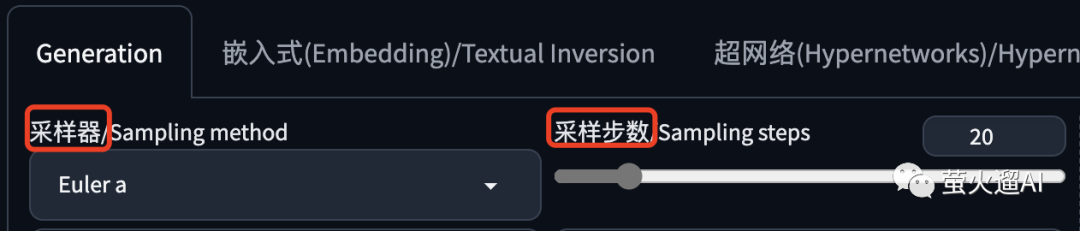
采样就是去除噪音。在上面介绍 Stable Diffusion 时,提到过“反向扩散”这个概念,采样器就是在反向扩散时去噪用的算法程序。
Stable Diffusion WebUI 中默认已经集成了很多采样器,比如:Euler a、DPM++、DDIM和Restart等等,它们在图像生成的效果和速度上存在一定的差异。比如:
Euler a:默认选中的就是这个,是最简单、最快的采样器,以较少的步数可以产生很大的多样性,不同的步数可能有不同的结果。但是,当步数过高时(超过30步),图像的质量可能不会有所提高。
DPM++:在图像的质量上表现不错,但相较于其他采样器,其耗时可能会相应增加。
随机数种子

随机数种子是AI绘画的魅力之一。在其它参数都相同的情况下,只要随机数不同,每次生成就会产生有些差异的图片,创意几乎无穷无尽;反过来使用相同的随机数则可以生成完全相同的图片,这也是很多人都对收集 Stable Diffusion 生图参数乐此不疲的原因。-1 代表每次使用不同的随机数。
在Stable Diffusion内部,随机数种子会影响潜在空间中的噪声图像。当其他参数完全相同时,相同的随机数种子将会生成相同的噪声图像,从而生成相同的像素图像。
OK,以上就是本文的主要内容,介绍了 Stable Diffusion 的一些基础概念。如果有感觉没讲清楚的地方,欢迎留言沟通;因能力有限,以上有些说法可能不准确或者存在错误,如有问题还望指正。

扫一扫,关注作者公众号
AI探索者,分享AI前沿知识跟实用技巧
相关文章
近期文章
更多

 Kardashian
Kardashian

 Altman
Altman







