 2023-09-07 16:53
2023-09-07 16:53
Stable Diffusion学习指南【文生图篇】丨咒语编写,参数设置
对体验过AI绘画的朋友们来说,提示词可以说是耳熟能详了,目前市面上的AI绘图工具基本都是围绕着文生图的基本功能展开的。不过相较于其他工具,Stable Diffusion的在咒语编写上会具有技巧性,相信大家在学习过程中都遇到过类似问题:复制别人的咒语但效果却很差、咒语的控图效果不理想、加了关键词但绘图结果却没有体现等。
别担心,在今天的教程里,我会为你详细的介绍Stable Diffusion文生图的操作方法以及提示词编写的语法技巧,保证你看完之后就能轻松成为一名专业的绘图魔法师?
在Stable Diffusion中,有文生图和图生图2种绘图模式,今天我们先来看看如何使用文生图来绘制我们想要的图片。下面是Stable Diffusion文生图界面的基础板块布局,如果你此前更换过主题相关的扩展插件,界面的功能布局可能会有所区别,但主要操作项都是相同的。
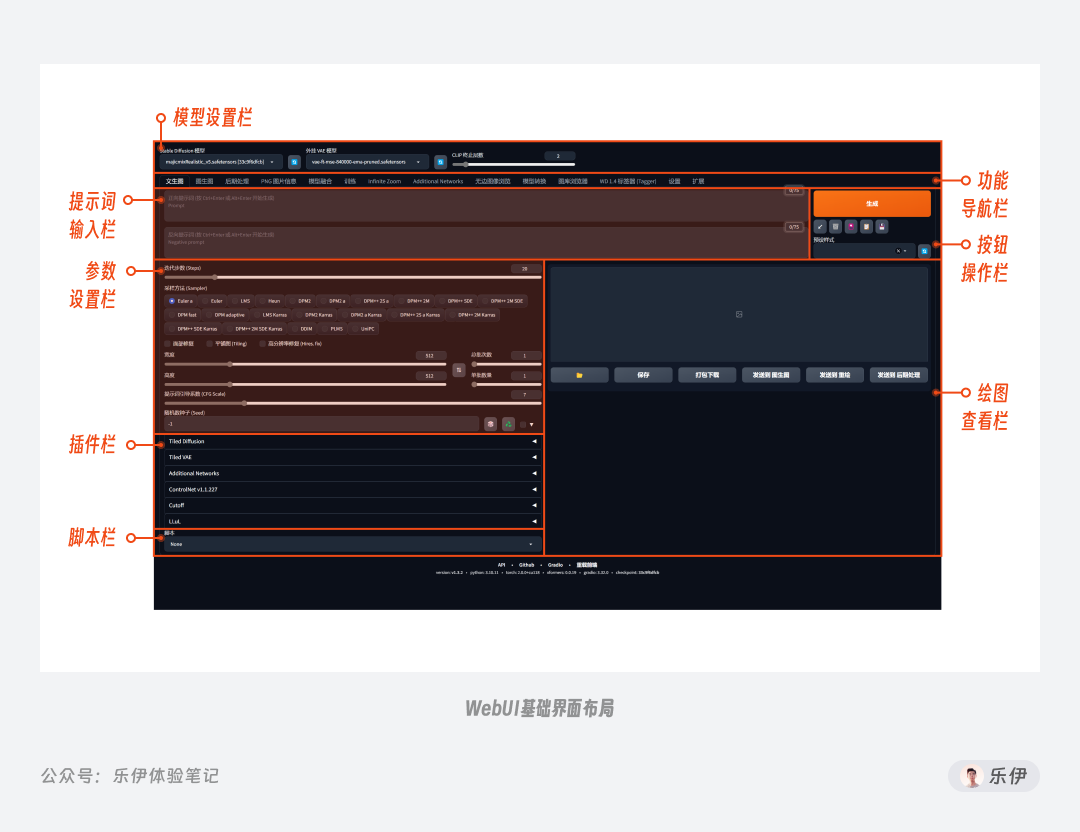
Stable Diffusion基础的操作流程并不复杂,一共就分成4步:选择模型—填写提示词—设置参数—点击生成。通过操作流程就能看出,我们最终的出图效果是由模型、提示词、参数设置三者共同决定的,缺一不可。其中,模型主要决定画风、提示词主要决定画面内容,而参数则主要用于设置图像的预设属性。
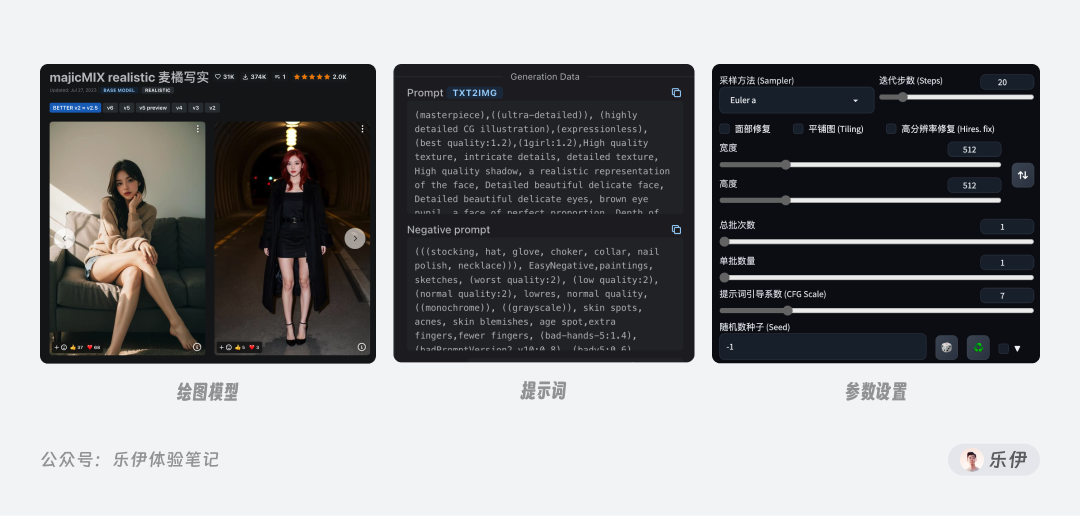
关于模型需要讲解的内容有很多,我会在后面的文章中单独进行介绍,今天我们重点关注提示词的写法以及各种设置参数的功能和含义,准备好了吗,下面让我们正式开始吧~
大家都知道,如今的AI工具大多是通过提示词来控制模型算法,那究竟什么是提示词?
对于人类而言,在经过多年的学习和使用后,我们只需简单的几句话便能轻松的沟通和交流。但如今的人工智能还是基于大模型的数据库进行学习,如果只是通过简单的自然语言描述,没有办法做到准确理解。为了更好的控制AI,人们逐渐摸索出通过反馈来约束模型的方法,原理就是当模型在执行任务的时候,人类提供正面或负面的反馈来指导模型的行为。而这种用于指导模型的信息,就被统称为Prompt提示词。

如今的AI工具都是基于底层大模型进行使用的,提示词的本质其实是对这个大模型的深入挖掘和微调,我们可以将它简单理解为人类和AI沟通的桥梁,因为模型反馈结果的质量在很大程度上取决于用户提供的信息量。当然这个问题主要还是底层大模型训练不够充分的缘故,像现在很多针对特定风格训练的应用级绘图模型,即使只有寥寥几个词也能绘制出优美的画作。如今很多企业为此还设立了单独的提示工程师岗位,在人工智能领域也有单独的一门学科叫做Prompt Engineering 提示词工程。
微软官方在最近也推出了一份完整的提示工程操作指南,感兴趣的朋友可以去深入学习一下:
对于细分到我们今天要聊的图像生成领域,提示词就是我们用来调节绘图模型的一种方法,通过输入想要的内容和效果,模型就能理解我们想表达的含义,从而实现准确的出图效果。
如今,大部分模型都是基于英文训练,因此输入的提示词大多只支持英文,中间也会夹杂了各种辅助模型理解的数字和符号。由于AI绘图无需经历手绘、摄影等过程就能凭空生成图片,国内最早一批AI爱好者贴切的将AI绘画过程比作施展魔法,提示词就是我们用来控制魔法的咒语,参数就是增强魔法效果的魔杖。
3.1 基础书写规范
相较于简单易上手的Midjourney,Stable Diffusion的咒语上除了prompt(正向关键词)外,还有Negative prompt反向关键词。顾名思义,正向提示词用于描述想要生成的图像内容,而反向关键词用于控制不想出现在图像中的内容,比如目前很多模型还无法理解的手部构造,为了避免出现变形,我们可以提前在反向关键词中输入手部相关的提示词,让绘图结果规避出现手的情况。不过目前很多反向提示词都已经集成到Embedding模型中,使用时只需输入模型触发词即可,在后续的文章中我会详细介绍。
前面我们提到Stable Diffusion只支持识别英文提示词,因此大家务必记住全程在英文输入法下进行输入,模型是无法理解中文字符的。但好消息是我们不用像学习英语时那样遵照严格的语法结构,只需以词组形式分段输入即可,词组间使用英文逗号进行分隔。除了部分特定语法外,大部分情况下字母大小写和断行也不会影响画面内容,我们可以直接将不同部分的提示词进行断行,由此来提升咒语的可读性。

在Stable Diffusion中,提示词默认并不是无限输入的,在提示框右侧可以看到75的字符数量限制。不过不用担心内容过长的问题,作者A41大佬提前在WebUI中预设好了规则,如果超出75个参数,多余的内容会被截成2段内容来理解。注意这里表示的并非75个英文单词,因为模型是按照标记参数来计算数量的,一个单词可能对应多个参数。
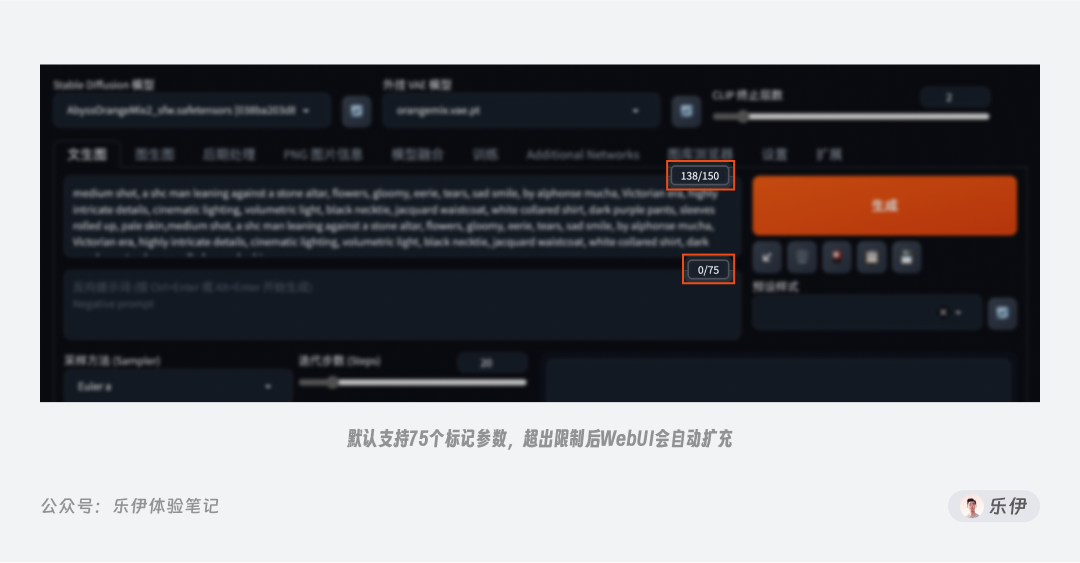
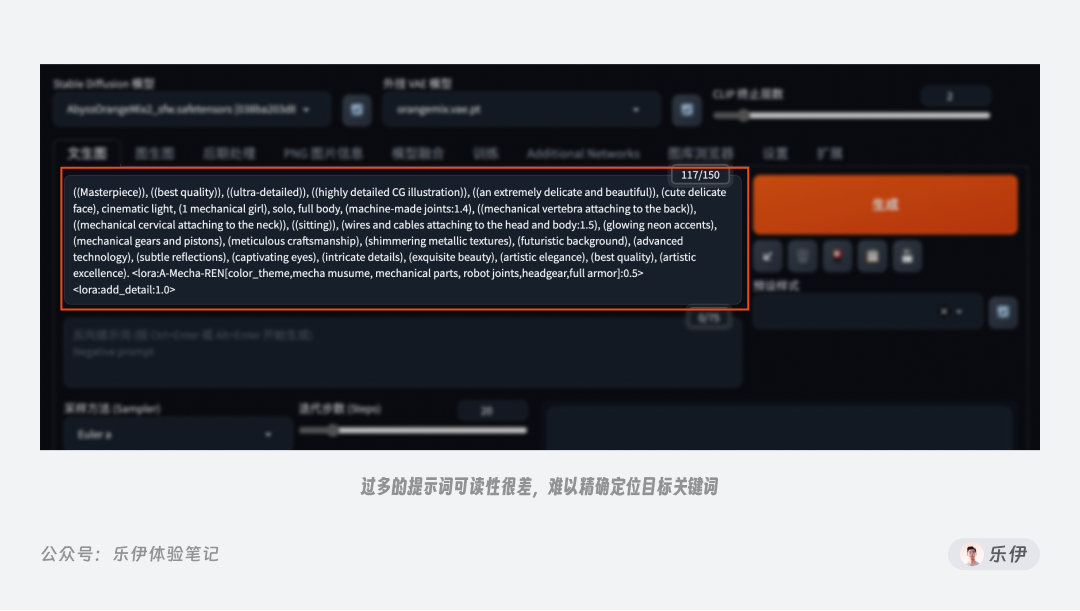
此外,提示词的内容并非越多越好,过多的提示词会导致模型在理解时出现语意冲突的情况,难以判断具体以哪个词为准,并且我们的绘图过程往往会根据出图效果不断修饰提示词内容,太多内容也会导致修改时难以精确定位目标关键词。
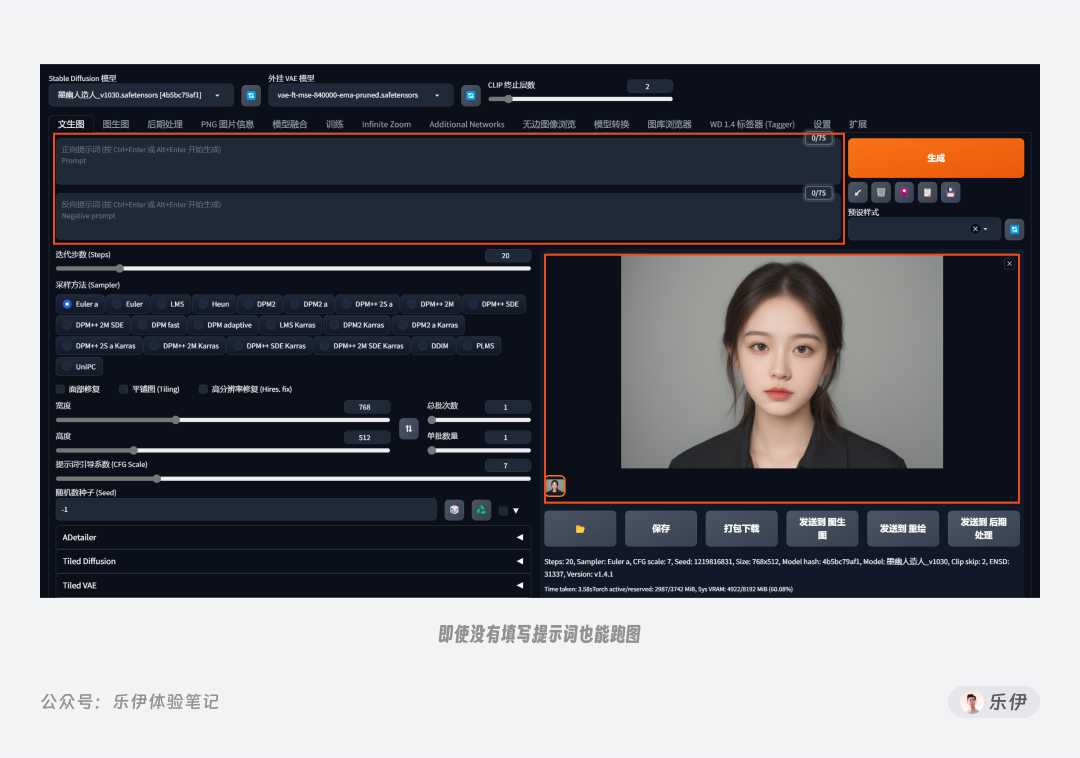
看到这里,你可能会担心提示词的编写过程会非常复杂。但实际上,SD的绘图过程是非常自由的。提示词的作用是引导和辅助模型的绘图过程,并非硬性要求,即使你的输入框没有填写任何内容,模型依旧可以为你画出一张图来,甚至可能效果还不错。
但如果想成为专业的魔法师,遵循一套标准的书写规范还是很有必要的:一方面完整且内容丰富的提示词可以让我们更好的控制最终出图效果,另一方面在后期微调过程中,也可以快速修改和验证特定关键词对出图结果的影响。
下面我会为大家介绍如何编写一段优雅的魔法咒语。
3.2 提示词的万能公式
一段能被模型清楚理解的好咒语首先应该保证内容丰富充实,描述的内容尽可能清晰。这个过程就像是甲方给我们布置任务,如果只说设计一张图,不说图中放什么,也不提图片是用来干嘛,我们会一脸懵逼无从下手。同理,Stable Diffusion在绘制图片时需要提供准确清晰的引导,提示词描述的越具体,画面内容就会越稳定。
在下面的例子中,如果我只是简单的写上【A girl】,对于画面中女孩着装、场景、镜头角度等内容都没有提及,Stable Diffusion只能根据模型训练时的历史经验自行发挥。得益于模型的强大,我们得到的绘图结果都还不错,但如果对画面内容有特定要求,这样抽奖的方式就效率很低了。

在下面的例子中,我们对提示词内容进行了丰富,描述了具体的场景和画面构图等信息后,出图结果明显稳定了许多。
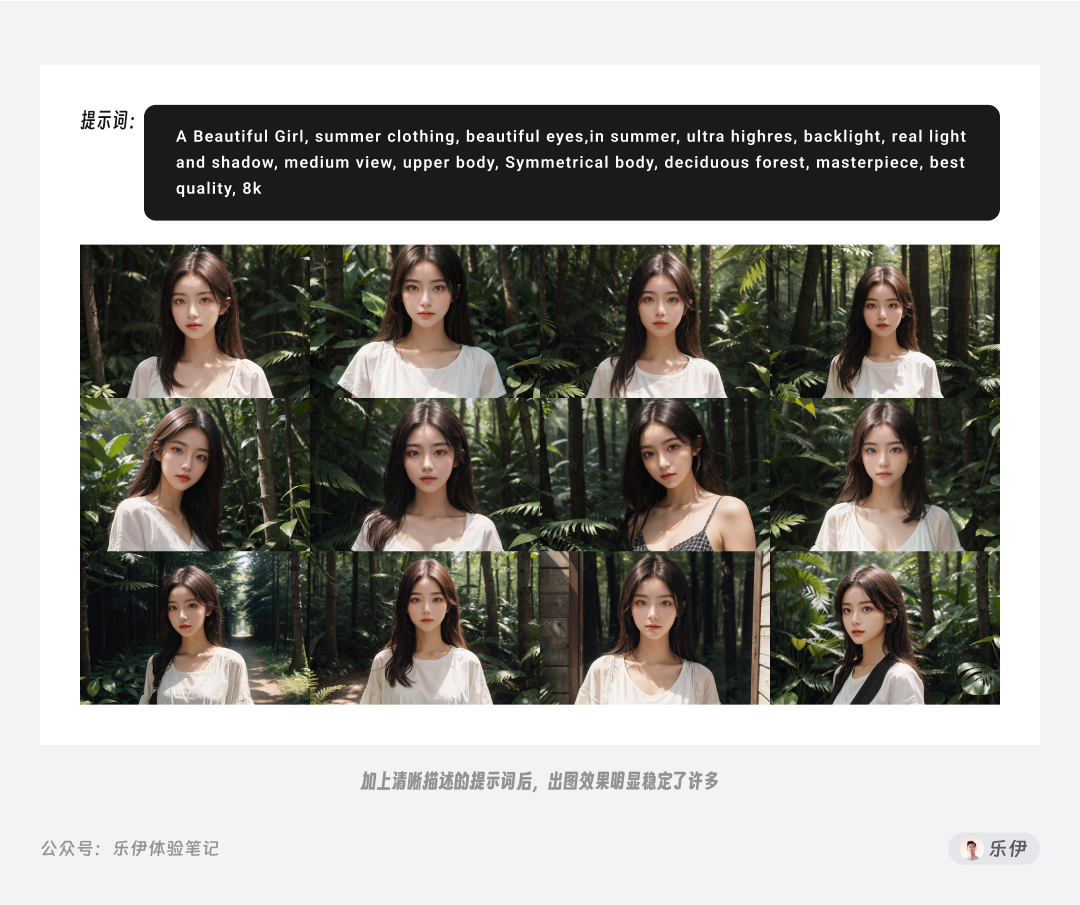
当然如果每次都是想到什么输什么,画面中可能还是会缺失很多信息,这里给大家分享一下我自己平时使用的提示词公式,按顺序分别为:主体内容、环境背景、构图镜头、图像设定、参考风格。后续在编写咒语时可以按照一下类目对号入座,会更加规范和易读。当然网络上也有许多其他博主分享的咒语公式,内容都大同小异,只要能满足出图需求即可。
需要注意的是,公式只是参考,并非每次编写咒语我们都要包含所有内容,正常的流程应该是先填写主体内容看看出图效果,再根据自己的需求来做优化调整。
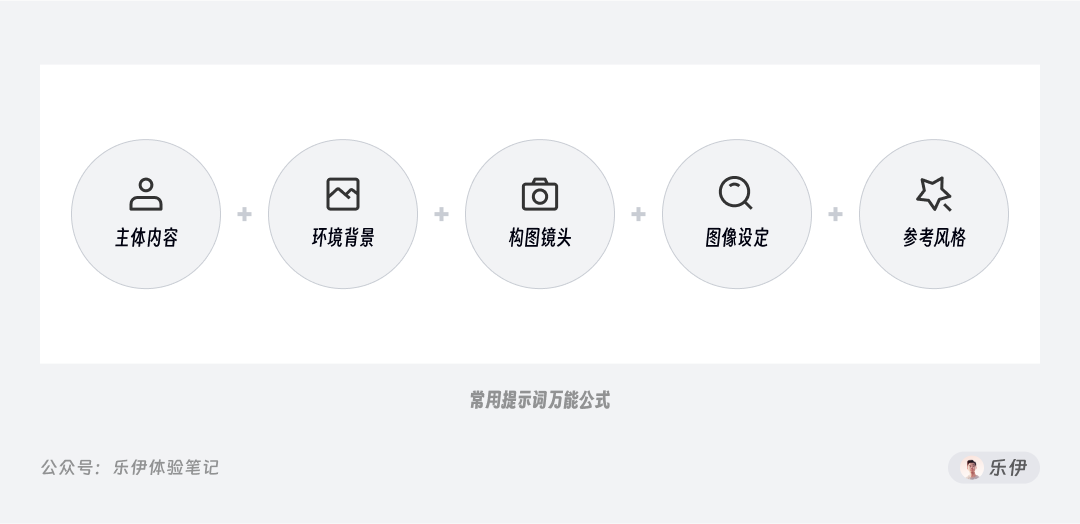
下面我们具体看下每个部分的信息,先说主体内容 ,这里是用于描述画面的主体内容,比如说是人或者动物,人物的着装、表情,动物的毛发、动作等,物体的材质等。一般同一画面中的主体内容不要超过2个,Stable Diffusion对多个物体的组合生成能力较弱,如果对画面内容有特定要求,可以先挨个生成主体素材进行拼合,然后用controlNet插件约束进行出图。
其次是环境背景 ,这个很好理解,就是设定周围的场景和辅助元素,比如天空的颜色、四周的背景、环境的灯光、画面色调等,这一步是为了渲染画面氛围,凸显图片的主题。
构图镜头 主要用来调节画面的镜头和视角,比如强调景深,物体位置等,黄金分割构图、中全景、景深。
图像设定 是增强画面表现力的常用词汇,我们经常在一些惊艳的真实系AI图片中看到比如增加细节、摄影画质、电影感等词,可以一定程度上提升画面细节。但注意最终图像的分辨率和精细度主要还是由图像尺寸来决定的,而本地运行的Stable Diffusion支持的绘图尺寸很大程度决定于显卡性能。如果电脑显卡算力跟不上,再多的关键词也弥补不了硬件差距,当然在Stable Diffusion中也有一些实现高清修复的小技巧,我会在后面的文章中为大家介绍。
最后就是参考风格,用于描述画面想呈现的风格和情绪表达,比如加入艺术家的名字、艺术手法、年代、色彩等。其实参考风格关键词在Stable Diffusion中使用的并不多,平时我们出图,多数情况下都是先选好特定风格的模型,然后根据模型作者提供的触发词强化风格。因为在Stable Diffusion中,图像风格基本是由模型决定的,如果此前该模型并没有经过艺术风格关键词的训练,是无法理解该艺术词含义的。
因此,大家如果对图像风格有要求,最好还是直接使用对应风格的模型来绘图,会比单纯使用提示词有效的多。
你可能会奇怪,为什么参考风格的关键词在Midjourney中效果会格外明显,这是由基础模型决定的。Midjourney调用的是官方服务器的超大模型,里面容纳了海量的训练数据,经过包罗万象的AI学习后基本各类风格的提示词都能理解,这也是为什么Midjourney如今的出图效果基本都很惊艳的原因。另一个典型的例子就是当我们在Midjourney中选择Niji模型时,即使加入高保真、3D等词汇,最终的出图效果也都是二次元画风的原因。

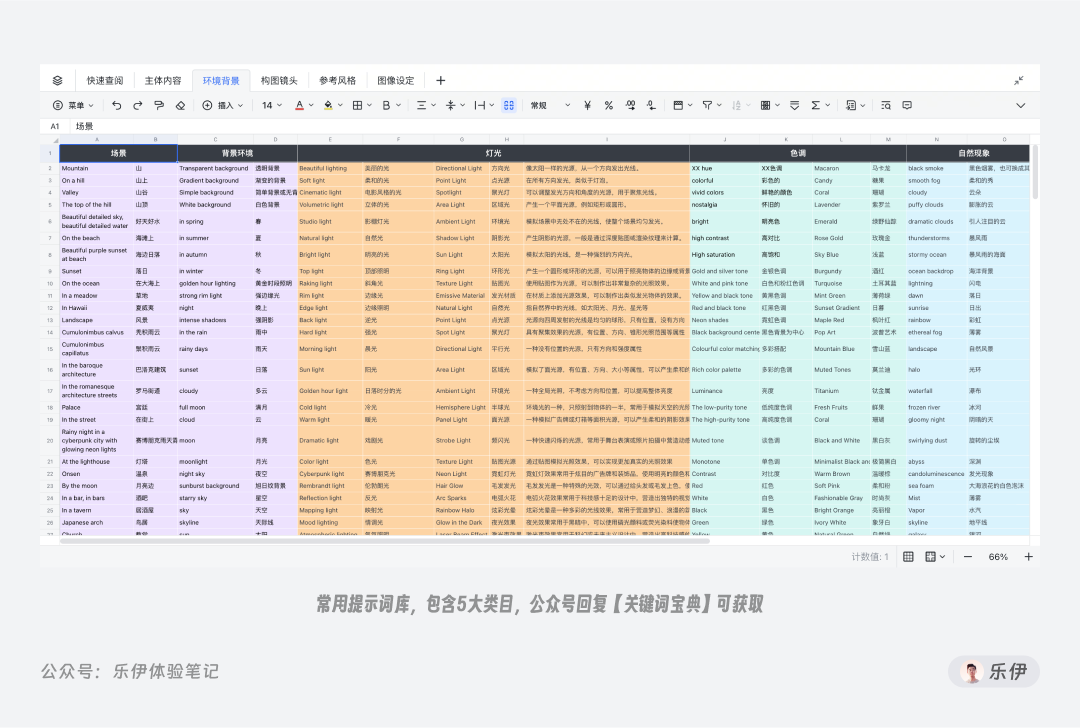
当然,如果每次编写咒语时都要背一次公式也太过麻烦。这里我搜集了网络上各类关键词,并结合自己使用经验整理了一套自用关键词文档,里面有3k+中英文对照词汇,大家平时在输入提示词时可以查找对应词条,基本能涵盖日常大多数的使用场景了,如果大家需要的话可以在公众号后台回复【关键词宝典】获取。
最后再提一点,我们最终的出图结果是由提示词、绘图模型和参数等共同决定的,不同模型对提示词的敏感度也不同,因此大家尽量结合模型特点灵活控制提示词的内容,比如对写实类模型可以多使用真实感等词汇,对二次元风格模型多使用卡通插画等词汇。
看到这里,你已经掌握了Stable Diffusion提示词的基础书写规则。但WebUI的强大并不止于此,作者“贴心”的为我们预设了很多更加高阶的玩法,掌握这些技巧可以让你更高效的控制模型出图,下面就是本篇文章的高能部分,记得做好笔记哦~
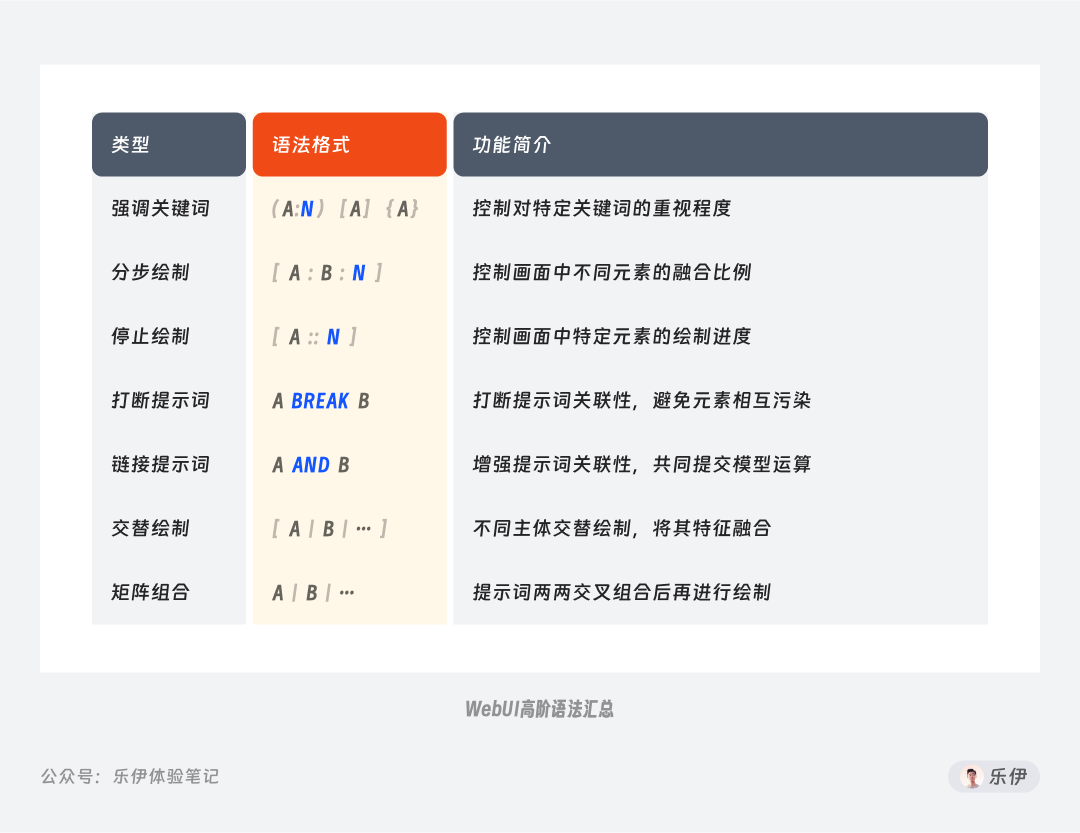
上图中我为大家整理汇总了Stable Diffusion常用语法的格式和功能说明,WebUI的高阶语法包括:强调关键词、分步绘制、停止绘制、打断提示词、链接提示词、交替绘制、提示词转义,由于是我自己理解后命名的功能,和作者的英文翻译会有部分差异,大家重点关注其语法和实际效果即可。
其中有些字符平时使用频率不高,这里也给大家提供键盘上对应字符按键的位置标注,以作参考。

4.1 强调关键词
先来看看强调关键词,这应该是使用最为频繁的语法了。强调关键词是依赖括号和数值来控制特定关键词的权重,当权重数值越高,说明模型对该关键词更加重视,在运行过程中模型就会着重绘制该部分的元素,在最终成像时图片中就会体现更多对应信息。反之数值越低,则最终图片中对应内容会展示的更少。
控制关键词的括号共有三种类型:圆括号()、花括号{}和方括号[],分别表示将括号内关键词的权重调整到原有的1.1倍、1.05倍和0.9倍。其中花括号{}平时很少会使用,一般都是用圆括号()和方括号[]。

需要注意的是,这里括号是支持多层叠加的,每层括号都表示乘以固定倍数的权重。

以下面这张图为例,默认情况下女孩的发色会是红色和金色结合成的橘红色,而当【blonde hair】加上表示提高权重的圆括号时,模型对金发部分的绘制会加强,最终图像里就出现更多金色的头发。

反之,【blonde hair】加上表示降低权重的方括号时,金发部分被减弱,模型在绘制时就会优先关注剩下的关键词【red hair】,所以最终图像里出现更多红色的头发。

除了直接加括号外,还有一种更常用的控制权重方法,那就是直接填写数值。

举个例子,下图默认情况下头发是呈现白、金、红三种颜色,如果我们在【white hair】后面设置权重为0.9.表示白发部分的权重降低为原来的0.9倍,则最终图像里白发部分的绘制会明显降低。

同理,我们增加红发和金发关键词的权重时,对应发色就会被加强。

虽然强调关键词语法支持的权重范围在0.1~100之间,但是过高和过低的权重都会影响出图效果,因此建议大家控制在0.5~1.5范围即可。
这里还有个快捷操作的小技巧,就是选中对应关键词后,按住ctrl+⬆️ / ⬇️,可以快速增加和减少权重数值,默认每次修改0.1.可以在设置中修改默认数值。
4.2 分步绘制
分步绘制在官方文档中的称呼是渐变绘制,但实际体验下来感觉叫做分步绘制会更好理解。该语法的原理是通过参数来控制整个绘制过程中用于绘制特定关键词的步数占比,语法格式如下:

关于迭代绘制步数我会在下面的参数设置中详细介绍,这里大家可以通过下面的例子来理解分布绘制语法的功能。
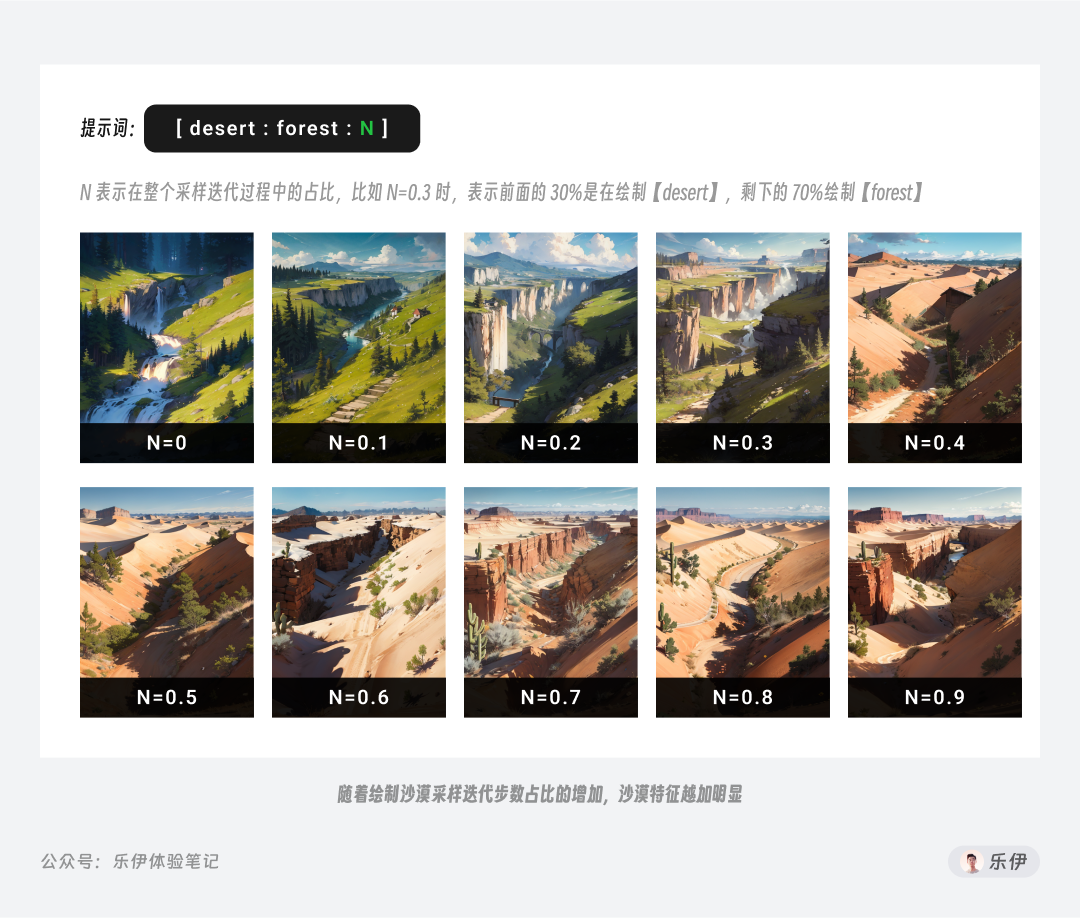
分布绘制可以控制画面中不同元素的融合比例,在上面的图片中可以看到,随着沙漠在采样迭代步数中占比的提升,接着绘制的森林元素已很难影响画面主体内容,基本都是沙漠元素。
4.3 停止绘制
停止绘制和分步绘制的原理相同,都是控制模型运行时绘制特定内容的步数占比。两者的区别在于:停止绘制只针对画面中单个关键词,并且是先绘制特定元素再移除,字符用的是2个冒号。

同样,我们结合下面的案例中来理解停止绘制语法的效果。
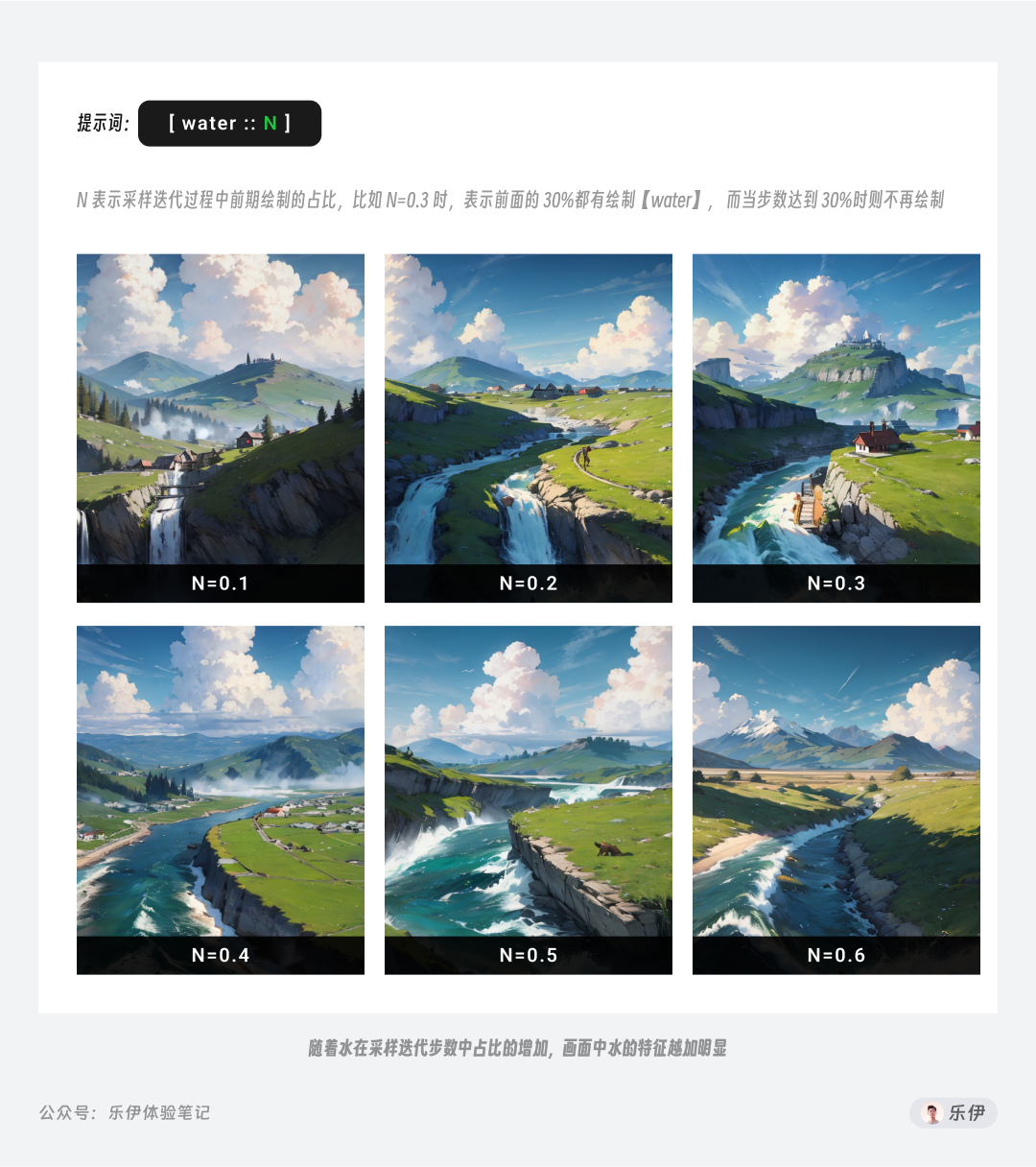
结合分步绘制和停止绘制的案例来看,在Stable Diffusion中模型绘制图像内容并非按照完美百分比的步骤进行绘制,画面内容在前面20步左右时已基本定型,后续的迭代步数更多是丰富细节,基本不会再添加或减少主体内容。
因此,对于需要优先展示的重要内容,大家尽量控制在迭代前期便开始绘制,否则后续很难在画面中体现。
4.4 打断提示词
打断的语法非常简单,也很好理解,就是在提示词之间加上关键词【BREAK】,它的作用时打断前后提示词的联系,在一定程度上减少提示词污染的情况。

Stable Diffusion模型在理解提示词时,并非像人类一样逐字逐句的阅读,而是会结合上下文内容来统一理解,这就导致在运行过程中有时候会出现前后关键词相互影响的情况,也就是我们俗称的污染。

通过加入【BREAK】,可以打断前后提示词的联系,模型会将前后内容分为2段话来理解,以下面这张图为例,可以看到我们在对女孩的服装进行了颜色指定,其中裤子的颜色被领带污染成了红色。而当我们在中间加入【BREAK】后,污染就被解除了,裤子呈现了正确的蓝色。

4.5 融合提示词
融合语法和打断正好相反,是将前后提示词的内容联系起来,模型在绘制时就会关联前后的元素特征,最终呈现出具备融合图像的特征。它的关键词是【AND】

到这里有的朋友可能会问,模型本身就是将一段提示词结合起来理解,为什么要额外加上【AND】呢?看完下面这个例子就很好理解了,可以发现如果只是通过逗号分隔,模型绘制时只是简单将黄色和绿色进行填充拼接,而加上【AND】后,模型会将黄色和绿色当作一个词来理解,最终绘制出草绿色。
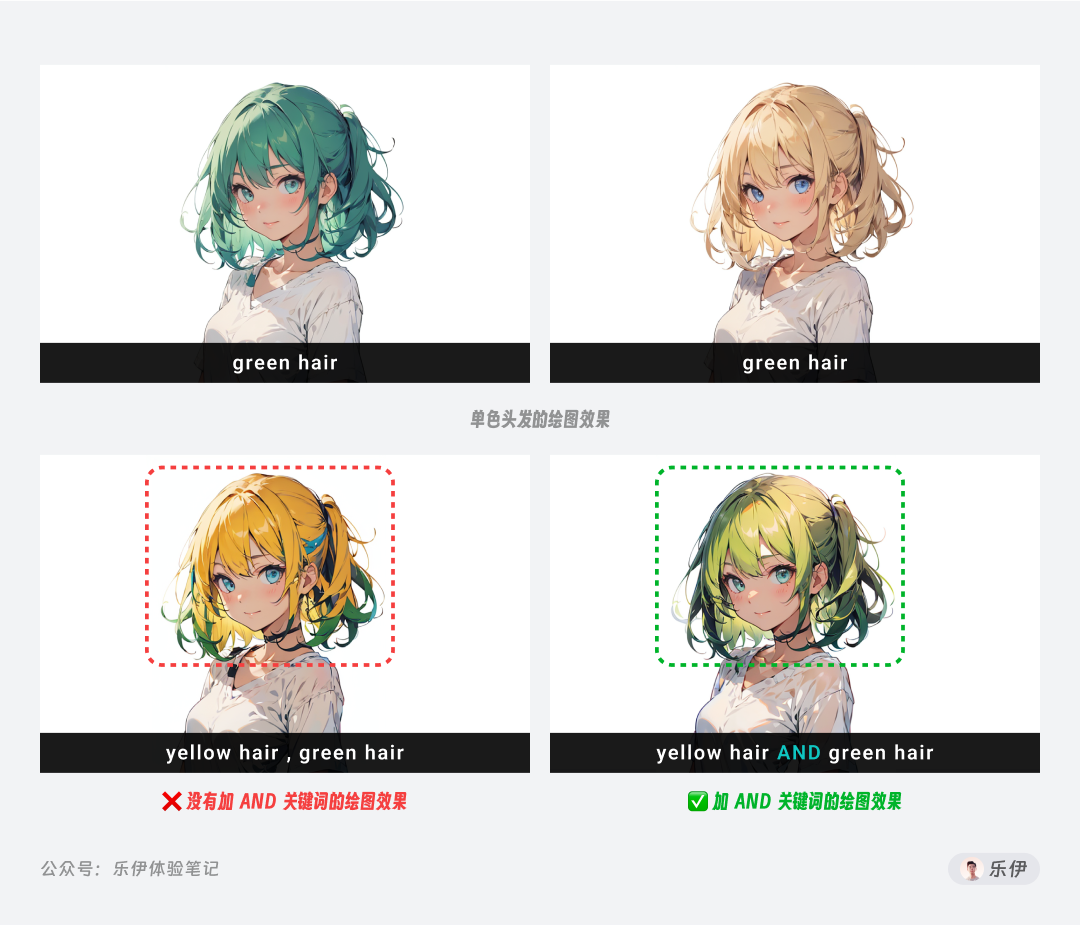
我们都知道黄色和绿色融合会呈现出草绿色,而模型在训练时有针对该内容进行深度学习,因此当【AND】链接前后关键词后就会将其以草绿色来理解,最终呈现出融合颜色的效果。
融合语法是非常强大的功能,颜色混合是其中一个方面的应用,大家在日常使用时可以灵活尝试。
4.6 交替绘制
除了融合外,还有一种语法也可以实现关键词融合的效果,那就是交替绘制。语法格式如下:

这里我们直接使用官方的案例来理解该语法的效果。通过观察迭代过程中的图像效果可以发现,模型在绘制时每一步迭代后都会切换用于绘制的关键词,而在这个过程中图像内容也被逐渐固定,最终呈现出又像牛又像马的融合怪。
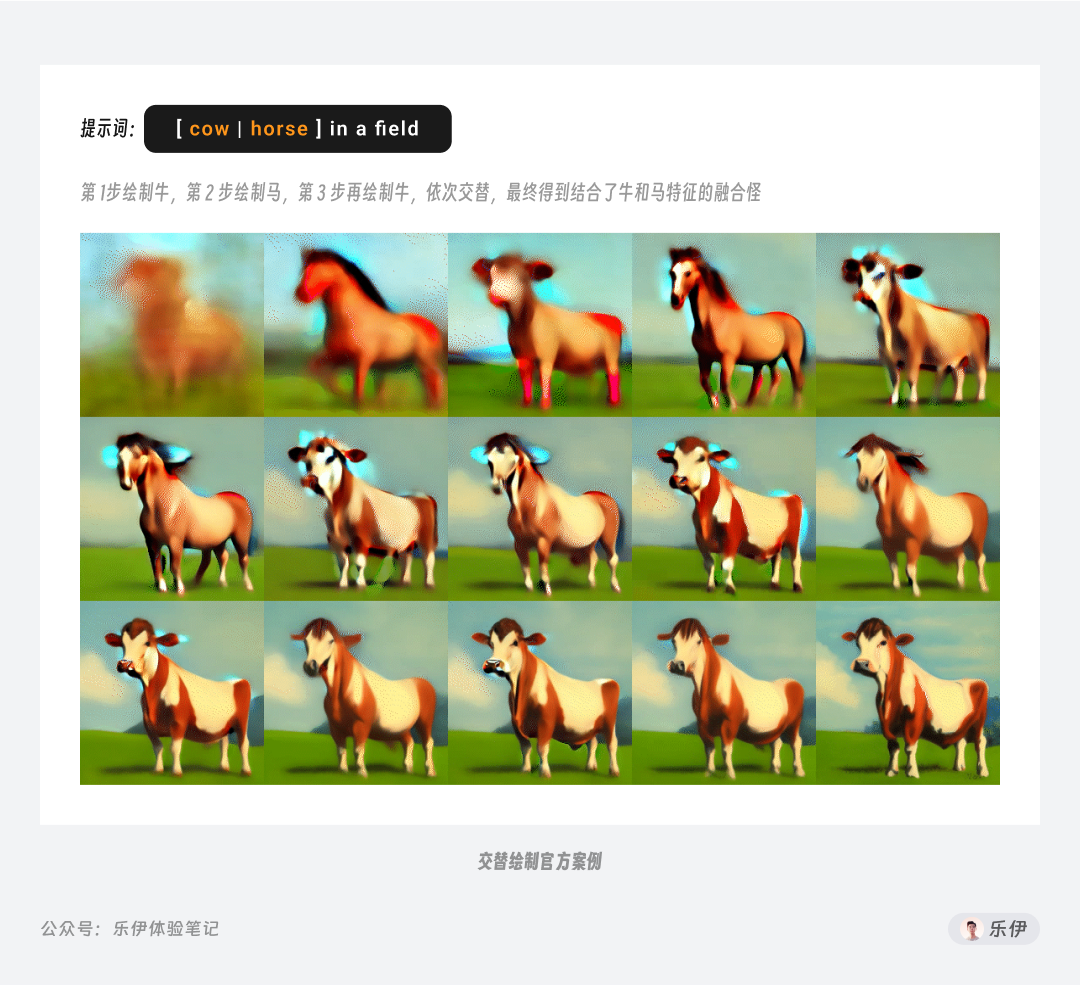
虽然同样是融合元素特征,但在原理上交替绘制和融合有本质区别:【交替】每步绘制时只理解单独的关键词,而【融合】是将前后的关键词一起来理解,因此交替最终呈现的效果更多是融合主体内容的画面特征,而无法像融合一样深度理解关键词之间的联系。我们平时在使用时一般主要也是使用融合语法【AND】居多,交替绘制更多是用于绘制比较猎奇的克苏鲁风格图像等。
4.7矩阵排列
最后就是矩阵排列的语法,该语法主要用于实现批量出图的效果,提高绘图效果。语法格式如下:

需要注意的是,该语法需要配合提示词矩阵Prompt matrix来使用,开启后按语法输入,模型会将关键词进行矩阵排列,每个组合的提示词都会生成一张对应的图像,若没有开启则会随机生成其中一张。
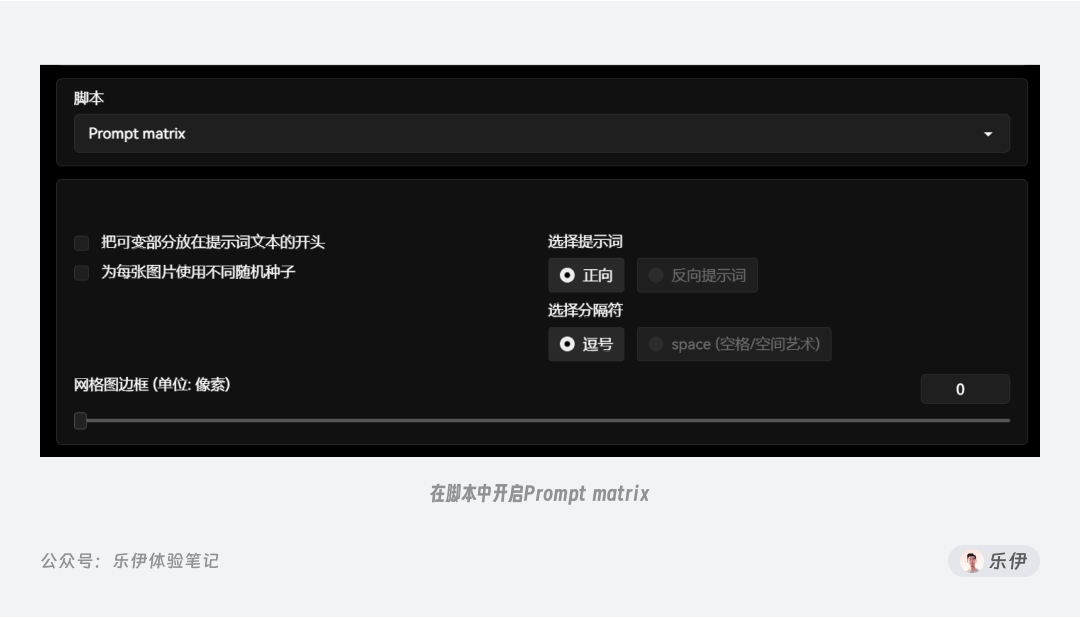
在下面的案例中可以看到,通过矩阵排列的提示词会依次组合生成多张图片。

以上就是我们平时常用的高阶语法啦,当然还有一些偏代码层的语法内容,不过平时用的不多,这里就不一一介绍啦,感兴趣的小伙伴也可以查阅WebUI作者整理的原版说明文档:
https://github.com/AUTOMATIC1111/stable-diffusion-webui
最后,我们再来看看文生图板块另一个十分重要的部分:参数设置。前面有提到参数的主要作用是设置图像的预设属性,这里的意思是WebUI作者将原本Stable Diffusion代码层常用于控制图像的参数进行了提取,通过滑块等可视化表单的方式来进行操控,这样就无需靠输入提示词来进行控制,使用起来更加便捷高效。
需要注意的是控制图像的参数其实有很多,这里只是作者预设的常用控制项,还有一些控图方法要装载其他脚本插件才能使用,我会在后面的教程中为大家介绍。
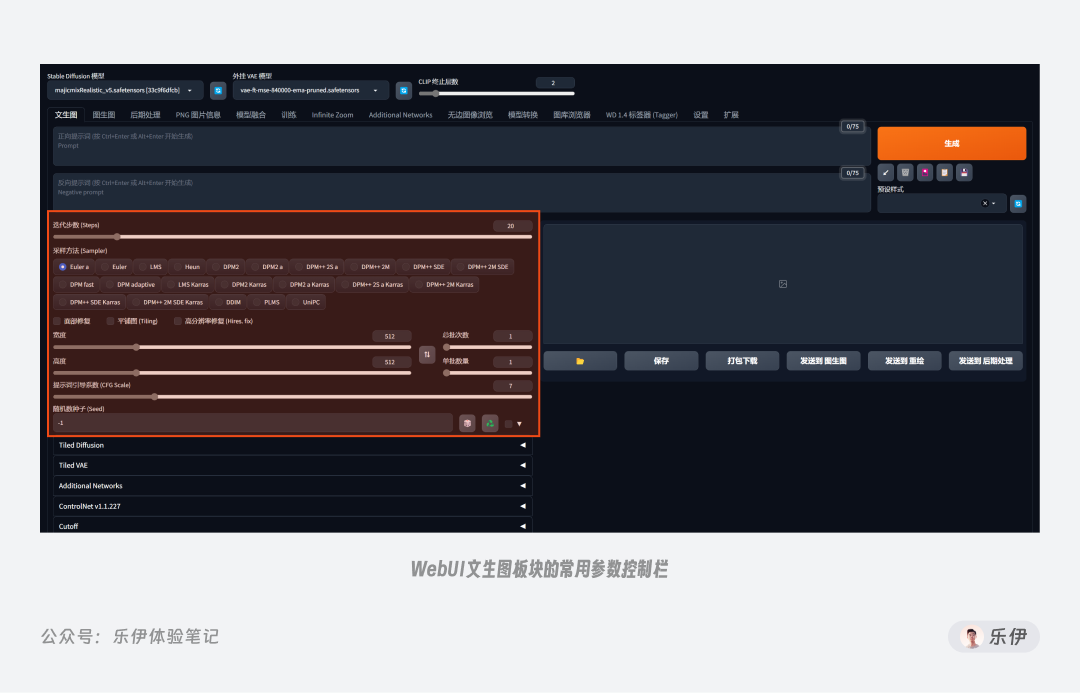
下面就跟我一起来看看这些预设项的功能和使用技巧吧~
5.1 采样迭代步数 Steps
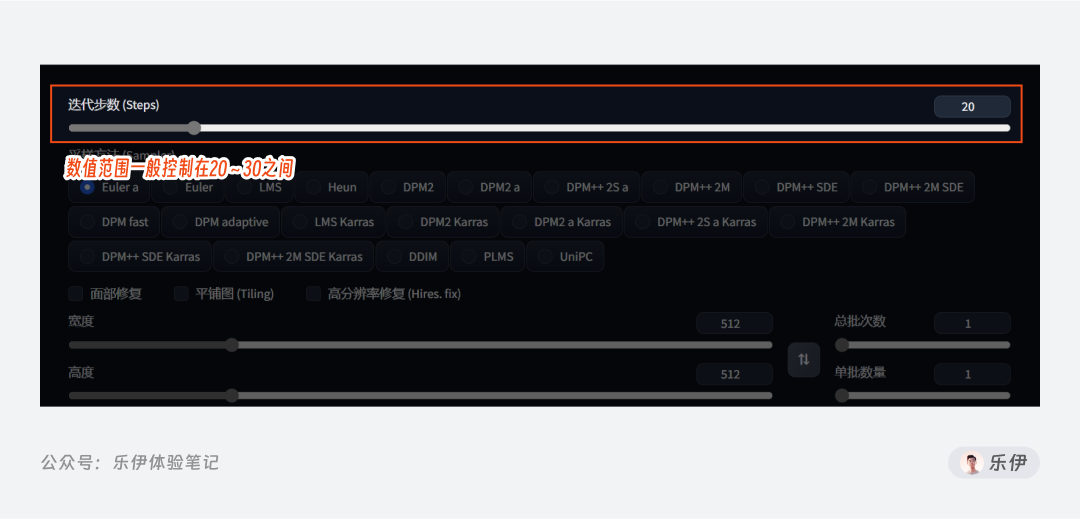
首先就是我们前面提到的采样迭代步数,在【初识篇】中我们有介绍扩散模型的绘制原理是逐步减少图像噪音的过程,而这里的迭代绘制步数就是噪音移除经过的步数,每一步的采样迭代都是在上一步的基础上绘制新的图片。
理论上来说,迭代步数越高表示去噪的过程越长,最终呈现的图像效果也就越精细,但实际上我们通常将步数都控制在40步以内。首先步数过小会导致图像内容绘制不够完整,很容易出现变形、错位等问题,而步数在迭代到一定次数时画面内容已基本确定(30步左右),后续再增加步数也只是优化微小细节,此外过高的步数也会占用更多资源,影响出图速度。
因此建议大家平时使用时,将采样迭代步数控制在20~30的范围内即可。
5.2 采样方法 Sampler
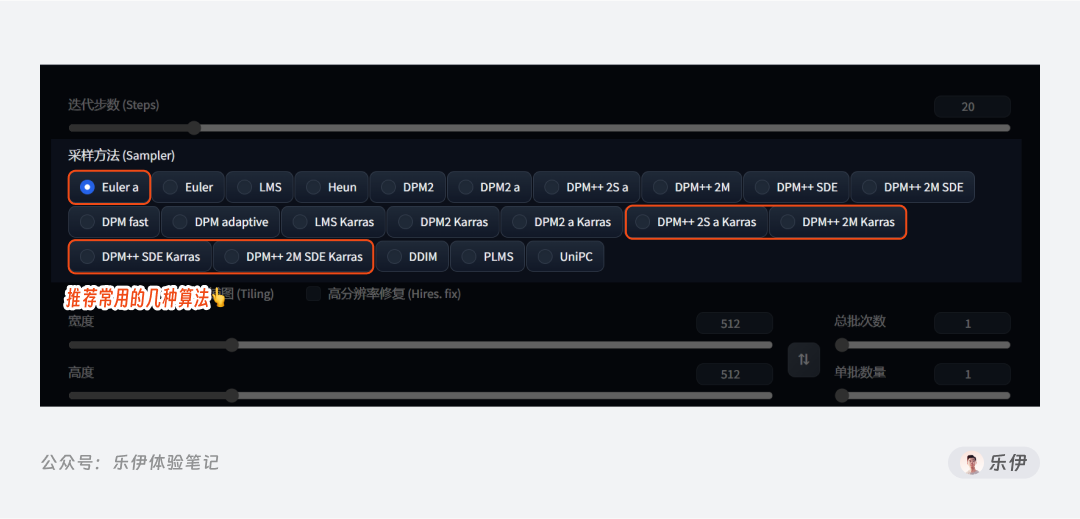
在之前的文章里我们知道Stable Diffusion模型的图像生成器里包含了U-Net神经网络 和 Scheduler采样算法 2个部分,其中采样算法就是用来选择使用哪种算法来运行图像扩散过程,不同的算法会预设不同的图像降噪步骤、随机性等参数,最终呈现的出图效果也会有所差异。
简单来说,选择采样算法是为了配合图像类型和使用的模型,来达到更佳的出图效果。WebUI中提供的采样算法有十几项,但我们平时常用的并不多,这里我也查阅了不少资料,发现大家推荐的算法类型并不一致,实际体验发现不同模型下算法的出图效果也不稳定,没有完全适合的固定算法一说。

下面的图中罗列了同一组提示词下所有的不同采样算法生成的图像对比,可以发现整体出图效果并没有太大差异,在实际使用时,给大家提供以下参考建议:
优先使用模型作者推荐的算法,比如深渊橘的作者最推荐使用的就是 DPM++ SDE Karras。
优先使用带加号的算法,作为优化算法会比不带加号的更加稳定
有选择恐惧症的小伙伴可以优先使用这几个推荐算法:Euler A、DPM+ +2S a Karras、DPM++ 2M Karras、DPM++ SDE Karras
5.3 面部修复 Face Restoration
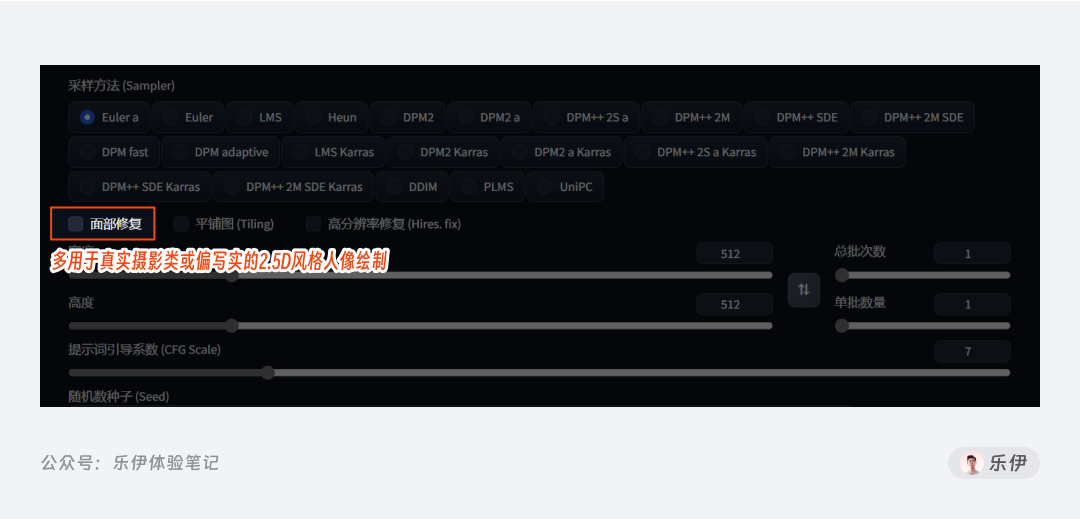
该设置项用于修复绘制过程中经常出现的面部扭曲问题,开启后模型会加强人物脸部的识别效果,因为二次元动漫人物的五官画风多样,算法的识别效果并不明显,该功能主要用于真实摄影类或偏写实的2.5D风格人像绘制。
实际上如今大多模型中已加强针对人脸的训练,反而开启面部修复或会对图像生成有一定干扰,所以在模型介绍页有的作者会特意加上避免开启面部修复的备注。
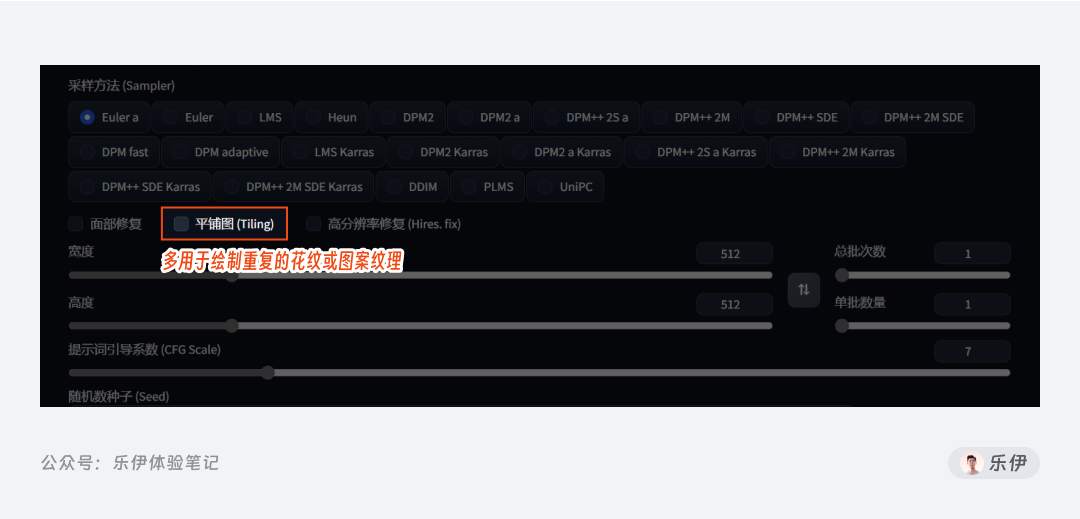
5.4 平铺/分块 Tiling
平铺类似Midjourney中的tile参数,用于绘制重复的花纹或图案纹理,平时用的不多。
5.5 宽高设置
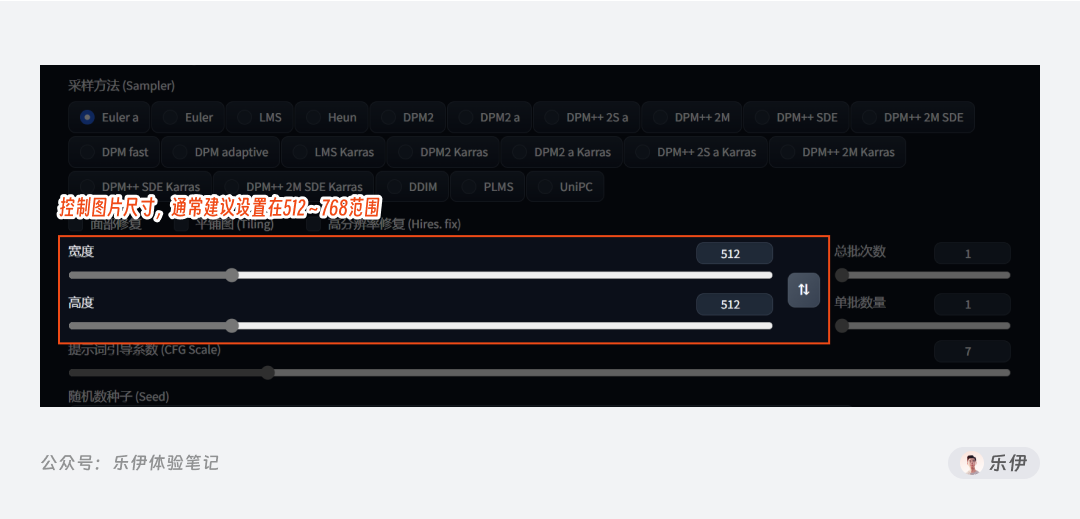
宽度和高度很好理解,就是最终生成的图像大小。
我们都知道,在分辨率恒定的情况下,图片的尺寸越大,可以容纳的信息就越多,最终体现的画面细节就越丰富。如果图片尺寸设置的较小,画面内容往往会比较粗糙,这一点在Stable Diffusion绘制真实人像、复杂纹理等元素时会格外明显。下面这张图可以看到,同一张图在放大尺寸重新绘制后,画面细节得到了显著提升。

但绘制大图的同时,显卡的运算负担也会加重,绘图时间会明显加长,过大的尺寸也容易出现黑图或爆显存等问题。此外,尺寸过大也会导致画面中出现多个人物或肢体拼接等问题。目前Stable Diffusion的大多数模型在训练时使用的是512*512像素大小图片,少部分会使用768*768.因此当图像尺寸超出一定范围,比如使用1536*512.模型在绘制图像时就会将其理解为是由多张图片拼接在一起,从而在一张图内塞入2~3张图片的内容,导致出现多人多肢体等问题。
这也是旧版模型的缺点之一,但在最近刚发布的SDXL官模中,已经对该问题进行了优化,相信再过段时间就能直接绘制大图了。

当然,以上问题目前也有解决方法,下面的高清修复就是解决方法之一。
5.6 高清修复 Hi-Res Fix
高清修复,也叫做高分辨率修复、超分(超分辨率),它是我们平时放大图片使用最频繁的功能之一。平时我们绘制图像,一般都是采用低分辨率先绘制,再开启高清修复进行放大。不同于我们平时的增加图像分辨率,高清修复的本质是进行了一次额外的绘图操作。该功能开启后会出现额外的操作栏,下图是简单的操作项介绍。
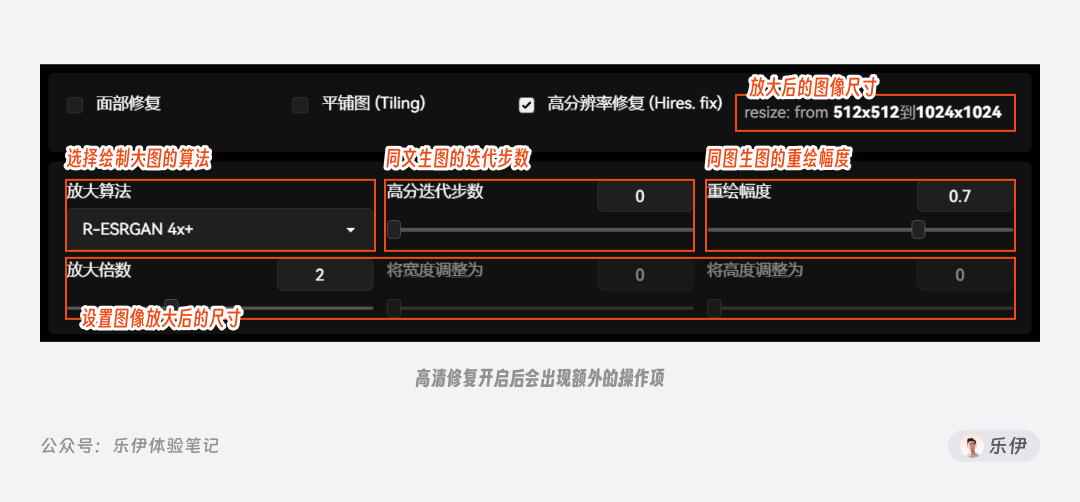
关于绘制高清大图的方法有很多,我会在后面的文章里进行统一介绍,这里就不再赘述了。
5.7 总批次数&单批数量
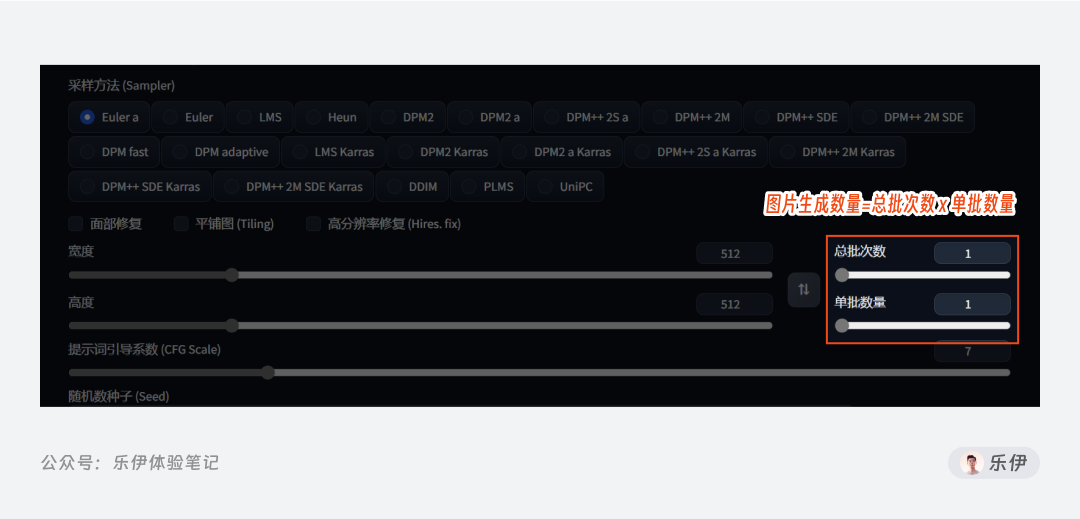
总批次数和单批数量可以放在一起来看,总批次数可以理解为同一提示词和设置项下触发几次生成操作,而每单批数量则表示每个批次绘制几张图片,因此总的图片生成数量=总批次数 x 单批数量。该功能主要是为了解决出图效率的问题,类似Midjourney中的repeat参数。由于模型绘图的结果存在很大的不确定性,想获取一张满意的图片往往要尝试多次,所以通过调整生成批次和数量,可以实现Stable Diffusion自动跑图,这样就无需每次绘图结束后再手动点击生成按钮。
其中,单批数量平时很少会修改,默认都是1张,更多时候是设置总批次数。因为每批生成的图片越多,相当于同一时间Stable Diffusion要绘制多张图片,其原理等同于绘制了一张大图,对显卡的要求会比较高,还不如每次只生成一张,然后用提高次数的方法来解决。

值得一提的是,调整多批次后,除了正常绘制的每张图,Stable Diffusion还会生成一张拼在一起的格子图,和Midjourney默认的四格图一样。
5.8 提示词相关性 CFG Scale
CFG Scale是用来控制提示词与出图相关性的参数,数值越高,则Stable Diffusion绘图时会更加关注提示词的内容,发散性会降低。
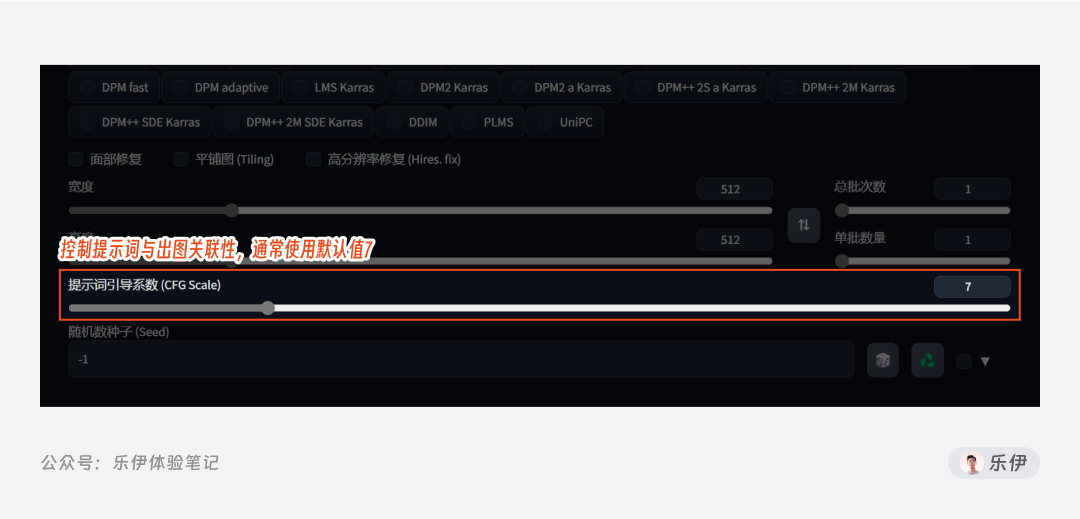
该功能支持的数值范围在0~30之间,但大多数情况下我们使用的数值会控制在7~12之间,正常情况下保持7不动即可。如果CFG数值过低或过高,都可能会导致出图结果不佳的情况。
5.9 随机种子 Seed
AI在绘图过程中会有很强的不确定性,因为每次绘制时都会有一套随机的运算机制,而每次运算时都对应了一个固定的Seed值,也就是我们俗称的种子值。在Midjourney中,种子值的随机性达到了42亿种可能,也就是说同一套提示词我们会获得42亿种随机结果,当然这和Midjourney本身庞大的训练数据库有关系。
而通过固定种子值可以锁定绘图结果的随机性,比如我们绘制了一张比较满意的图片时,可以将调用其种子值填写在这里,可以最大程度的保证原图的画面内容。
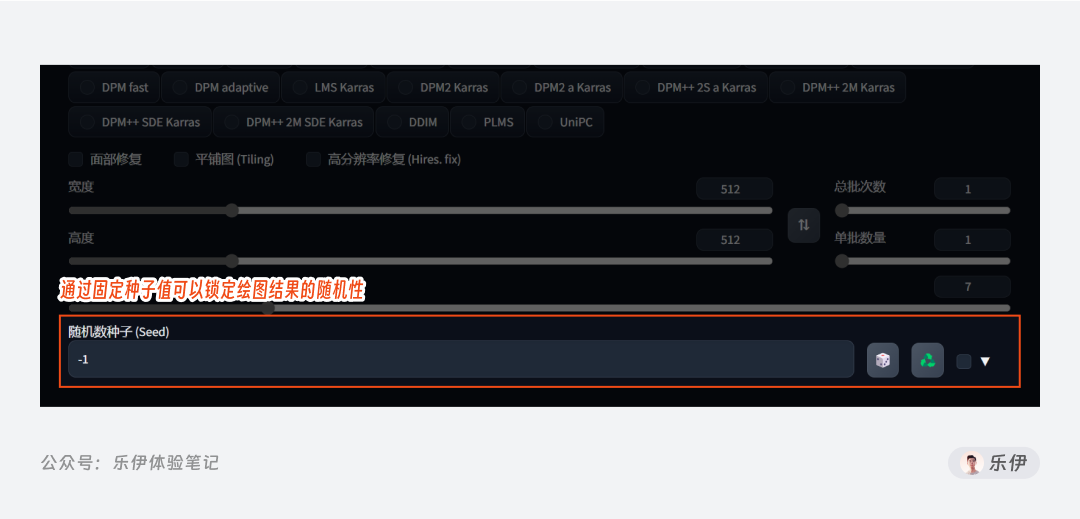
在右侧有2个按钮,点击骰子?可以将seed重置为默认的-1.也就是随机的状态。回收♻️按钮则是将最后绘制的图片seed值固定在这里。
? 结束撒花 ?
到这里本篇教程就全部结束啦,在今天的文章里我给大家介绍了提示词的基本语法和书写规则以及一些更高阶的语法技巧,关于文生图的各类参数也进行了介绍。因为里面的不少知识点加入了我自己的理解,可能在表述上有一定差异,如果你有其他建议或想法的话,也欢迎在评论区给我留言~
相关文章
近期文章
更多

 Kardashian
Kardashian

 Altman
Altman







